
Analytics/Server Admin Log
2024-07-23
[edit]- 18:58 milimetric: done deploying refinery-source, deploying airflow dags now
2024-07-22
[edit]- 13:27 ottomata: restarting eventlogging-processor on eventlog1003 - something is wrong with the consumer...https://phabricator.wikimedia.org/T353817#10002205
- 08:17 brouberol: deploy istio (adding securityContext) to dse-k8s-eqiad cluster - T362978
2024-07-17
[edit]- 16:59 btullis: deploying airflow-dags to pick up https://gitlab.wikimedia.org/repos/data-engineering/airflow-dags/-/merge_requests/762 for T367949
- 15:44 ottomata: deploying refinery to pick up bump to gobblin wmf
- 08:45 btullis: stopping mariadb section 1-8 on clouddb1021 for T368518
2024-07-16
[edit]- 20:34 ottomata: disabled produce_canary_events systemd timer to unblock mw on k8s. airflow should suffice now. T370186
- 10:18 btullis: restarted `cirrussearch-dump-s5.service` on snapshot1017 after fixing issue with aewikimedia search indices for T362529
2024-07-11
[edit]- 13:18 btullis: setting cephosd cluster to noout mode for T365996
- 13:17 btullis: draining dse-k8s-worker1007 ready for T365996
- 13:14 btullis: failed back hive and presto services to an-coord1003
- 10:09 btullis: swapping an-mariadb100[1-2] roles back.
- 09:29 btullis: temporarily disabled gobblin ingestion to facilitate an-mariadb role swap.
2024-07-10
[edit]- 10:10 btullis: proceeding with an-mariadb role swap as per https://phabricator.wikimedia.org/T365503#9965173
- 08:55 btullis: temporarily pausing gobblin timers in advance of an-mariadb role switch
2024-07-09
[edit]- 16:20 btullis: deploying refinery to hdfs
- 16:02 btullis: Starting the refinery deployment
- 13:41 btullis: rebooting an-worker1080 for T366555
- 12:19 btullis: failing over hive and presto to the standby coordinator for T348977
2024-07-08
[edit]- 10:21 btullis: rolling out conda-analytics version 0.0.35 for T369240 and T369210
2024-07-03
[edit]- 19:08 SandraEbele_: deploying airflow dags
2024-07-02
[edit]- 15:50 btullis: failing over hadoop yarn resourcemanager from an-master1004 to an-master1003
- 15:49 btullis: failing over hadoop namenode from an-master1004 to an-master1003
- 10:26 btullis: rebooting an-master1003 (current standby namenode and resourcemanager) for T366555
- 10:04 btullis: killing stuck gobblin jobs
2024-06-26
[edit]- 18:07 xcollazo: 'Deployed latest DAGs to analytics Airflow instance.'
- 18:01 xcollazo: Deployed refinery using scap, then deployed onto hdfs
- 16:26 xcollazo: Deploying refinery using scap
- 16:12 xcollazo: Deployed refinery-source using jenkins
- 11:47 stevemunene: deploy conda-analytics v 0.0.32 to analytics airflow hosts T356231 T356230
- 11:33 stevemunene: deploy conda-analytics v 0.0.32 to analytics stat hosts T356231 T356230
- 11:22 stevemunene: deploy conda-analytics v 0.0.32 to analytics hadoop coordinator hosts T356231 T356230
- 11:12 stevemunene: deploy conda-analytics v 0.0.32 to analytics hadoop worker hosts T356231 T356230
- 10:23 stevemunene: debdeploy conda-analytics 0.0.32 to test cluster T356231
2024-06-18
[edit]- 15:02 mforns: deployed airflow analytics to update CIM category allow-list
- 14:23 btullis: commencing roll-reboot of an-presto workers for T366555
- 07:42 stevemunene: update miniconda version on `an-test-client` T356231
2024-06-17
[edit]- 13:56 joal: deleting old canary event job now that the new one has a new name
- 13:00 joal: Deploy analytics-airflow for webrequest jar version bump
2024-06-13
[edit]- 16:28 btullis: started copying sqldata.s1 from clouddbd1021 to an-redacteddb1001 for T365453
2024-06-12
[edit]- 21:06 ryankemper: performing rolling reboot of analytics workers: `ryankemper@cumin2002:~$ sudo -E cookbook sre.hadoop.reboot-workers analytics`
2024-06-11
[edit]- 17:49 amastilovic: Deployed refinery-source using jenkins
- 16:15 ryankemper: performing rolling reboot of an-test-worker cluster
- 13:41 btullis: decommissioning stat1007 for T367147
- 12:59 btullis: decommissioning stat1006 for T367147
- 11:08 btullis: decommissioning stat1004 for T367147
2024-06-06
[edit]- 19:31 xcollazo: Deploying latest DAGs to the analytics Airflow instance. T358707.
- 10:31 joal: Manually launching an import of wikidata-xml-history dump for date 20240501
2024-06-05
[edit]- 17:30 btullis: re-enabling XML dumps on snapshot10[10-13]
- 10:16 btullis: switching stat100[4-7] into insetup::buster role for T353785
2024-06-04
[edit]- 12:30 stevemunene: delete WikiKube datahub release T361185
2024-06-03
[edit]- 09:44 btullis: reimagaing snapshot1013 to bullseye for T325228
2024-05-31
[edit]- 19:35 btullis: dumpsgen@clouddumps1002:/srv/dumps/xmldatadumps/public$ find . -maxdepth 2 -wholename '*/20240520' -exec rm -rf {} \; (disabling tomorrow's XML dumps for T365155)
2024-05-30
[edit]- 17:36 joal: Unpause webrequest after deploy
- 17:36 joal: Deploy airflow revert of webrequest hive version change
- 16:20 joal: Pause webrequest airflow dag to rollback a change
- 16:03 joal: Delete old "reportupdater_browser_all_sites_weekly" DAG from airflow (lefover from reportupdater migration, renamed to browser_metrics_weekly/grid
- 15:37 joal: deploying airflow dags
- 13:42 joal: deploy refinery onto HDFS
- 12:29 joal: Deploy refinery using scap
- 09:31 joal: release refinery-source v0.2.41 on archiva
2024-05-29
[edit]- 16:59 stevemunene: deploy airflow-dags to analytics instance to Change the datahub ingestion url T366135
- 14:04 stevemunene: getting started on moving datahub to dse-k8s T361185
2024-05-28
[edit]- 07:53 joal: manually rerun clickstream job for 2024-04 to pick up linktarget data that was not present at the moment it ran automatically (T366042)
2024-05-23
[edit]- 12:46 joal: Deleting airflow variable for canary_event_hourly job to update artifact to latest version
- 09:47 btullis: reimaging stat1008 to bullseye
2024-05-22
[edit]- 08:48 btullis: deploying AQS device-analytics for T360531
2024-05-21
[edit]- 10:37 joal: Deploy refinery on an-launcher1002 after reimage
- 09:10 btullis: Upgrading an-launcher1002 to bullseye
2024-05-20
[edit]- 15:35 mforns: finished deploying refinery for https://gerrit.wikimedia.org/r/c/analytics/refinery/+/1027525
- 14:37 mforns: deploying refinery for https://gerrit.wikimedia.org/r/c/analytics/refinery/+/1027525
2024-05-16
[edit]- 15:53 btullis: moving the `dumps::generation::worker::dumper_misc_crons` role from snapshot1008 to snapshot1017 for T325228
2024-05-15
[edit]- 10:06 btullis: deploying airflow analytics instance
- 10:06 btullis: deploying airflow analytics_test instance
- 09:49 btullis: deploying refinery to hdfs
- 08:47 btullis: deploying refinery with refinery source version 0.2.40
2024-05-14
[edit]- 11:52 btullis: re-running refine_eventlogging_legacy for `event`.`centralnoticeimpression` /wmf/data/event/centralnoticeimpression/year=2024/month=5/day=13/hour=18
2024-05-08
[edit]- 17:04 sfaci: Deployed refinery-source using jenkins
- 16:57 sfaci: Deployed refinery using scap, then deployed onto hdfs
- 16:21 sfaci: Deploying refinery
2024-05-07
[edit]- 14:05 btullis: unpaused cassandra_load_pageview_per_project_hourly for T362181
- 14:03 btullis: deploying airflow analytics instance for T362181 to fix cassandra cipher list
- 12:04 btullis: deploying airflow analytics instance for https://gitlab.wikimedia.org/repos/data-engineering/airflow-dags/-/merge_requests/678 and T362181
2024-05-01
[edit]- 15:59 milimetric: deploying airflow dags to play with mediawiki snapshot config cassandra loader job
2024-04-30
[edit]- 17:59 xcollazo: starting deploy of refinery...
- 17:21 xcollazo: aborting deploy of refinery due to scap global lock held by T358636. Will attempt again in about an hour.
- 16:58 xcollazo: starting deploy of refinery...
- 16:54 xcollazo: Deployed refinery-source using jenkins
2024-04-29
[edit]- 20:59 mforns: deployed airflow-dags/analytics
- 20:22 mforns: finished refinery deployment (with v0.2.37 jars)
- 19:11 mforns: started refinery deployment (with v0.2.37 jars)
- 18:38 mforns: deployed refinery-source v0.2.37
2024-04-26
[edit]- 11:08 btullis: removed the symlink `/srv/published/datasets/periodic/reports` on an-launcher1002 to cease publishing reportupdata jobs from this host (T307540)
- 09:50 joal: Deploy Airflow browser-metrics fix
2024-04-25
[edit]- 15:34 mforns: deployed airflow analytics to fix commons_impact_metrics_monthly DAG
2024-04-24
[edit]- 15:55 SandraEbele_: Deployed refinery using scap, then deployed onto hdfs.
- 15:00 SandraEbele_: starting refinery deployment
- 12:27 btullis: shutting down stat1010 to allow the GPU power cable to be fitted for: T336040
- 09:08 elukey: run 'kill `pgrep -u dbad2021`' on all stat nodes to unblock puppet
2024-04-23
[edit]- 12:59 stevemunene: deploy conda-analytics v 0.0.29 to analytics-airflow hosts T362648
- 12:50 stevemunene: deploy conda-analytics v 0.0.29 to analytics stat hosts T362648
- 12:13 stevemunene: deploy conda-analytics v 0.0.29 to hadoop test cluster T362648
2024-04-22
[edit]- 14:58 mforns: deployed Airflow analytics for commons impact metrics dump dag
- 14:40 mforns: finished deployment of refinery for Commons Impact Metrics dumps queries
- 13:47 mforns: starting deployment of refinery for Commons Impact Metrics dumps queries
2024-04-18
[edit]- 18:10 joal: Rerun canary-events on previous hour to test patch
- 18:10 joal: Re-deploy airflow for canary-event scaling
- 17:42 joal: Rerun cacnry-events on previous hour to test patch
- 17:37 joal: DEploy airflow for canary-event scaling
- 16:57 btullis: switching matmo service from matomo1002 to matomo1003
- 14:07 btullis: restarted the hadoop-yarn-resourcemanager.service on an-master100[3-4] to pick up new queue settings for T361499
- 11:41 btullis: adding new 'launchers' yarn queue and renaming 'fifo' to 'gpus' for T361499
- 09:30 mforns: finished refinery deployment for commons impact metrics changes (0.2.36)
- 08:10 mforns: starting refinery deployment for commons impact metrics changes (0.2.36)
2024-04-17
[edit]- 21:47 mforns: don't have time to deploy refinery today, will do it tomorrow first thing
- 21:40 mforns: Deployed refinery-source using jenkins
- 08:40 aqu: Deployed refinery using scap, then deployed onto hdfs
- 08:00 stevemunene: enable puppet on an-test-client1002 done testing new conda anaytics deb T362648
- 07:39 aqu: analytics/refinery deploy begin (added source jars 0.2.35)
- 07:37 stevemunene: disable puppet on an-test-client1002 to test new conda anaytics deb T362648
2024-04-16
[edit]- 20:08 aqu: Weekly deploy of refinery using scap, then deployed onto hdfs
- 15:00 btullis: kicked off a rolling restart of the hadoop worker datanode and nodemanager process for T356382
- 14:40 btullis: failed back HDFS namenode from an-master1004 to an-master1003.
- 11:02 stevemunene: upgrade datahub to v0.12.1 T361688
- 09:16 btullis: restarting mapreduce history service on an-master1003 for T356382
2024-04-15
[edit]- 11:05 btullis: sudo systemctl start hadoop-hdfs-namenode.service on an-master1003 after failed failback operation.
- 10:45 btullis: roll-restarting hadoop masters on the prod cluster for T356382
- 08:54 btullis: roll-restarting hadoop masters on test cluster for T356382
- 08:36 btullis: roll-restarting druid on test cluster for T356382
2024-04-11
[edit]- 15:25 btullis: restarting hive-server2 and hive-metastore on an-test-coord1001 for T356382
- 14:10 elukey: move cassandra instances on aqs1010 to PKI TLS certs
- 12:21 btullis: deploying editor-analytics with the new aqs-http-gateway chart
2024-04-09
[edit]- 13:20 btullis: shut down stat1010 to have the GPU power connected for T336040
- 12:56 gmodena: successfully deployed refinery to hadoop and hadoop-test
- 12:06 gmodena: starting a refinery deployment for 2024-04-09
2024-04-08
[edit]- 15:43 btullis: decommissioning dumpsdata1002 for T362065
- 15:25 btullis: decommissioning dumpsdata1001
- 12:00 btullis: rebooting stat1011 due to unresponsiveness
2024-04-03
[edit]- 11:46 stevemunene: disable puppet on `an-test-client1002` to test new conda-analytics version T356231
2024-03-28
[edit]- 18:04 btullis: deploying refinery to HDFS.
- 16:22 btullis: deploying refinery to test the git-lfs integration with scap for T328472
- 15:00 elukey: remove GPU labels in Hadoop Yarn for an-worker[1096-1099] (the hosts don't have a GPU anymore) - T361225
2024-03-27
[edit]- 15:14 brouberol: decommissioning an-tool1009 now that hue is fully offline - T341895
- 15:02 brouberol: dropping the hue.wikimedia.org CNAME - T341895
2024-03-25
[edit]- 15:02 btullis: updating the ssl_provider for eventstreams schema servers to cfssl for T360412
2024-03-22
[edit]- 13:17 elukey: `elukey@cumin1002:~$ sudo cumin 'stat100[4,5,8,9]*' 'kill `pgrep -u kcv-wikimf`'` to unblock puppet on various stat nodes
- 10:44 btullis: shut down an-worker1168 to investigate disk controller failure for T360594
2024-03-20
[edit]- 10:50 brouberol: superset.wikimedia.org is now migrated to the DSE k8s cluster, CAS errors have receeded
- 10:20 brouberol: migrating superset to Kubernetes. Some CAS errors are expected during ~15 minutes
2024-03-07
[edit]- 14:01 btullis: deploying updated mediwiki_history_reduced snapshots to AQS 2.0
2024-03-04
[edit]- 12:22 btullis: restarting hive-server2 and hive-metastore service on an-coord1003
- 12:00 btullis: migrating analytics-hive from an-coord1003 to an-coord1004 with https://gerrit.wikimedia.org/r/c/operations/dns/+/1008414
- 10:32 btullis: restart hive-server2 and hive-metastore service on an-coord1004
2024-02-29
[edit]- 14:06 btullis: sudo systemctl reset-failed refinery-sqoop-whole-mediawiki.service
- 09:59 joal: Deploying refinery with scap (fix sqoop for tomorrow)
- 09:25 brouberol: decommissioning an-tool1005 now that superset-next is migrated to k8s - T358706
2024-02-28
[edit]- 11:08 btullis: reimaging dbstore1007 to bookworm for T356961
- 09:48 joal: Deploying refinery onto HDFS
- 09:28 joal: Deploying Refinery for T357859
2024-02-27
[edit]- 18:14 tchin: deploying eventstreams
2024-02-22
[edit]- 11:52 brouberol: redeploying the spark-history server with expanded egress rules for hadoop workers - T358206
2024-02-21
[edit]- 21:21 joal: Update airflow variable for pageview_actor-hourly leading to 64 written files instead of 32 - this should ease the job resource consumption and prevent failures
- 19:51 joal: Rerun pageview_actor_hourly for hour 2024-02-20T07:00
2024-02-20
[edit]- 22:52 sfaci: Deployed refinery using scap, then deployed onto hdfs
- 22:18 sfaci: Starting refinery deployment
- 15:57 xcollazo: deployed latest Airflow DAG updates for the analytics instance
2024-02-19
[edit]- 11:14 sfaci: rerunning the compute_pageview_actor_hourly task in the pageview_actor_hourly DAG 2024-02-17 08:00:00 UTC
2024-02-13
[edit]- 09:03 brouberol: attempting a reimage of apifeatureusage1001 to bookworm - T346053
2024-02-09
[edit]- 14:01 brouberol: superset was successfully deployed once the MySQL password was updated - T347710
- 13:47 brouberol: deploying superset/superset-next services in dse-k8s-eqiad - T347710
2024-02-08
[edit]- 09:50 stevemunene: failover hadoop namenode back to an-master1003 T353776
2024-02-07
[edit]- 20:17 joal: Relaunch session_length_daily failed task
- 20:09 joal: Relaunch druid_load_unique_devices_per_domain_daily_aggregated_monthly after deploy
- 19:49 joal: deploying Refinery onto HDFS
- 19:49 joal: Deployed refinery using scap
- 19:49 joal: Release refinery-source v0.2.32
- 17:26 btullis: roll-restarting kafka-jumbo for T356382
- 15:35 btullis: rolling out a change of the discovery-uri to presto workers and clients https://gerrit.wikimedia.org/r/c/operations/puppet/+/998425
- 13:01 stevemunene: failover hadoop namenode back to an-master1003 after the jvm service restart to pick up new JDK and T353776
- 12:48 stevemunene: restart jvm services on an-master1003 for T353776 and to pick up new JDK
- 12:36 stevemunene: failover hadoop namenode to an-master1004 for jvm service restart to pick up new JDK and T353776
- 12:24 stevemunene: restart jvm services on an-master1004 for T353776 and to pick up new JDK
2024-02-06
[edit]- 19:57 joal: Deploy refinery onto HDFS
- 19:34 joal: Deploying refinery using scap
- 19:34 joal: Refinery-source v0.2.31 released to archiva
- 14:57 btullis: roll-restarting the presto workers for T356382
- 14:04 joal: Rerun mediawiki-history-reduced druid indexation after airflow variable update
- 13:39 brouberol: add new TLS SANs to the superset/superset-next certificates in dse-k8s-eqiad - T356481
- 13:29 stevemunene: roll restart hadoop masters to pick up the right rack assignment for new hosts T353776
- 11:45 stevemunene: add new an-workers to analytics_cluster hadoop worker role analytics_cluster::hadoop::worker T353776
- 11:03 btullis: reimaging an-web1001 to bullseye for T349398
2024-02-05
[edit]- 14:07 btullis: deploying conda-analytics version 0.0.28 to hadoop-all for T345482
- 13:50 brouberol: increasing pod & container limits in the dse-k8s-eqiad superset/superset-next namespaces - T352166
- 12:37 btullis: roll-restarting druid analtyics workers for T356382
- 12:35 btullis: deploying conda-analytics version 0.0.28 to hadoop-test
2024-02-02
[edit]- 10:27 btullis: correction: reimaging an-airflow1002to bullseye for T335261
- 10:27 btullis: reimaging an-airflow10042to bullseye for T335261
- 09:46 btullis: reimaging an-airflow1004 to bullseye for T335261
2024-02-01
[edit]- 13:40 btullis: roll-restarting zookeeper on druid-analyticsfor T356382
- 13:34 btullis: roll-restarting zookeeper on druid-public for T356382
- 13:25 btullis: roll-restarting zookeeper on an-conf* for T356382
- 12:35 joal: Rerun refinery-sqoop-whole-mediawiki after hotfix
- 12:30 joal: hotfix HDFS sqoop list to prevent an entire redeploy
- 12:08 joal: Restart refinery-sqoop-whole-mediawiki.service after deploy
- 11:29 phuedx: Deployed refinery onto hdfs
- 11:21 btullis: deploying the new spark-operator images based on JRE 8 for T354273
- 10:55 phuedx: phuedx@deploy2002 Finished deploy [analytics/refinery@0d8e976] (hadoop-test): Remove trvwikisource from scoop list (duration: 03m 30s)
- 10:51 phuedx: phuedx@deploy2002 Started deploy [analytics/refinery@0d8e976] (hadoop-test): Remove trvwikisource from scoop list
- 10:51 phuedx: phuedx@deploy2002 Finished deploy [analytics/refinery@0d8e976] (thin): Remove trvwikisource from scoop list (duration: 00m 05s)
- 10:51 phuedx: phuedx@deploy2002 Started deploy [analytics/refinery@0d8e976] (thin): Remove trvwikisource from scoop list
- 10:50 phuedx: phuedx@deploy2002 Finished deploy [analytics/refinery@0d8e976]: analytics/refinery: Remove trvwikisource from scoop list (duration: 10m 20s)
- 10:39 phuedx: phuedx@deploy2002 Started deploy [analytics/refinery@0d8e976]: analytics/refinery: Remove trvwikisource from scoop list
- 10:08 btullis: deploying Superset 3.1.0 to an-tool1010 with https://gerrit.wikimedia.org/r/c/analytics/superset/deploy/+/994213
- 09:49 joal: deploying airflow for interlanguage_navigation in Iceberg
2024-01-31
[edit]- 19:59 joal: Deploying refinery with scap for second hotfix
- 19:14 joal: Backfill wmf_traffic.aqs_hourly
- 19:14 joal: Drop/Recreate wmf_traffic.aqs_hourly table (iceberg) to change compression format
- 18:40 phuedx: phuedx@deploy2002 Finished deploy [airflow-dags/analytics@5078a6b]: (no justification provided) (duration: 00m 28s)
- 18:40 phuedx: phuedx@deploy2002 Started deploy [airflow-dags/analytics@5078a6b]: (no justification provided)
- 17:46 phuedx: Deployed refinery using scap, then deployed onto hdfs
- 17:40 joal: pause pageview_actor_hourly for deploy
- 17:35 phuedx: phuedx@deploy2002 Finished deploy [analytics/refinery@bef134c] (hadoop-test): Regular analytics weekly train TEST [analytics/refinery@bef134c2] (duration: 03m 29s)
- 17:31 phuedx: phuedx@deploy2002 Started deploy [analytics/refinery@bef134c] (hadoop-test): Regular analytics weekly train TEST [analytics/refinery@bef134c2]
- 17:31 phuedx: phuedx@deploy2002 Finished deploy [analytics/refinery@bef134c] (thin): Regular analytics weekly train THIN [analytics/refinery@bef134c2] (duration: 00m 08s)
- 17:31 phuedx: phuedx@deploy2002 Started deploy [analytics/refinery@bef134c] (thin): Regular analytics weekly train THIN [analytics/refinery@bef134c2]
- 17:30 phuedx: phuedx@deploy2002 Finished deploy [analytics/refinery@bef134c]: Regular analytics weekly train [analytics/refinery@bef134c2] (duration: 11m 05s)
- 17:19 phuedx: phuedx@deploy2002 Started deploy [analytics/refinery@bef134c]: Regular analytics weekly train [analytics/refinery@bef134c2]
- 17:02 phuedx: phuedx@deploy2002 Finished deploy [analytics/refinery@2c00cad] (hadoop-test): Regular analytics weekly train TEST [analytics/refinery@2c00cad1] (duration: 03m 35s)
- 17:00 phuedx: phuedx@deploy2002 Started deploy [analytics/refinery@2c00cad] (hadoop-test): Regular analytics weekly train TEST [analytics/refinery@2c00cad1]
- 16:57 phuedx: phuedx@deploy2002 Finished deploy [analytics/refinery@2c00cad] (thin): Regular analytics weekly train THIN [analytics/refinery@2c00cad1] (duration: 00m 06s)
- 16:57 phuedx: phuedx@deploy2002 Started deploy [analytics/refinery@2c00cad] (thin): Regular analytics weekly train THIN [analytics/refinery@2c00cad1]
- 16:53 phuedx: phuedx@deploy2002 Finished deploy [analytics/refinery@2c00cad]: Regular analytics weekly train [analytics/refinery@2c00cad1] (duration: 09m 52s)
- 16:52 phuedx: Regular analytics weekly train [analytics/refinery@$(git rev-parse --short HEAD)]
- 12:12 btullis: rebooting dbstore1009 for new kernel version (T356239)
- 11:56 btullis: rebooting dbstore1008 for new kernel version (T356239)
- 10:57 btullis: deploying https://gerrit.wikimedia.org/r/c/analytics/superset/deploy/+/994213 to superset-next to test nested display of presto columns
2024-01-30
[edit]- 18:48 xcollazo: ran the following commands to create a production test dump folder:
- 18:46 xcollazo: deployed latest DAG changes to analytics Airflow instance
- 10:17 btullis: upgrading an-airflow1005 (search) to bullseye for T335261
- 09:59 gmodena: starting a scap deployment of analytics airflow dags
- 09:31 brouberol: yarn.wikimedia.org is back
- 09:00 brouberol: reimaging an-tool1008, causing unavailability of the yarn.wikimedia.org UI for the duration of the op - T349399
2024-01-29
[edit]- 13:06 brouberol: I'm starting the reimaging process of an-tool1009.eqiad.wmnet, which will cause unavalability of hue.wikimedia.org while it runs - T349400
- 10:46 btullis: upgrading an-airflow1007 to bullseye for T335261
2024-01-24
[edit]- 15:21 aqu: Refinery weekly deployment train - end (scap, then deployed onto hdfs) (test cluster deploy still broken T354703)
- 14:31 aqu: Refinery weekly deployment train - begin
2024-01-16
[edit]- 16:36 gmodena: starting refinery deployment using scap
- 16:35 gmodena: Deployed refinery-source v0.2.28 using jenkins. Jars are on archiva.
- 15:46 gmodena: releasing and deploying refinery source v0.2.28
2024-01-15
[edit]- 17:02 btullis: roll-restarting public druid cluster
- 17:01 btullis: roll-restarting analytics druid cluster
- 16:55 joal: Clearing analytics failed aiflow tasks after fix
- 16:47 btullis: restarted the hive-server2 and hive-metastore services on an-coord100[3-4] which had been accidentally omitted earlier for T332573
- 12:00 btullis: removing all downtime for hadoop-all for T332573
- 11:57 btullis: un-pausing all previously paused DAGS on all airflow instances for T332573
- 11:55 btullis: re-enabling gobblin jobs
- 11:38 brouberol: redeploying the Spark History Server to pick up the new HDFS namenodes - T332573
- 11:29 btullis: puppet runs cleanly on an-master1003 and it is the active namenode - running puppet an an-master1004.
- 11:20 btullis: running puppet on an-master1003 to set it to active for T332573
- 11:16 btullis: running puppet on journal nodes first for T332573
- 11:03 btullis: stopping all hadoop services
- 10:59 btullis: disabling puppet on all hadoop nodes
- 10:54 btullis: putting HDFS into safe mode for T332573
2024-01-10
[edit]- 12:47 stevemunene: roll restarting hadoop test workers to pick up new JRE
- 12:22 stevemunene: decommission druid1006.eqiad.wmnet T354743
- 12:05 stevemunene: decommission druid1005.eqiad.wmnet T354742
- 11:39 stevemunene: decommission druid1004.eqiad.wmnet T354741
2024-01-09
[edit]- 21:28 aqu: airflow-dags/analytics(_test) are both deployed
- 21:18 aqu: analytics/refinery not deployed fully on test cluster. Ticket for the bug here: https://phabricator.wikimedia.org/T354703
- 21:07 aqu: Deployed refinery using scap, then deployed onto hdfs
- 20:48 aqu: about to deploy analytics/refinery - weekly train
- 12:57 stevemunene: roll restart analytics hadoop masters to pickup new net_topology script and new JRE T254480
- 11:48 stevemunene: roll restarting hadoop test masters to pick up new net_topology script and new JRE
- 11:36 stevemunene: disable puppet on hadoop masters both test and production to test/implement new net_topology script
- 10:39 btullis: roll-restarting kafka-jumbo to pick up new JRE
2024-01-08
[edit]- 17:22 btullis: migrated s1-analytics-replica to dbstore1008 for T351921
- 17:19 btullis: migrated s5-analytics-replica to dbstore1008 for T351921
- 15:56 btullis: migrating s7-analytics-replica to dbstore1008 for T351921
2024-01-03
[edit]- 10:32 btullis: restarted the monitor_refine_event.service on an-launcher1002 to clear alert
2024-01-02
[edit]- 15:36 btullis: migrating analytics-hive.eqiad.wmnet to an-coord1003 for T336045
- 10:56 brouberol: configuring [eqiad,codfw].mediawiki.cirrussearch.page_rerender.v1 as compacted topics on jumbo-eqiad - T353715
- 09:24 btullis: adding three days' downtime to dbstore1008, prior to switching its role to `mariadb::analytics_replica` for T351921
2024-01-01
[edit]- 17:11 joal: Deploying airflow to fix pageview daily aggregated monthly job
2023-12-22
[edit]- 21:38 mforns: re-ran the Airflow DAG cassandra_load_unique_devices_daily for 2023-12-14
- 21:37 mforns: re-ran the Airflow DAG druid_load_unique_devices_per_domain_daily for 2023-12-14
- 21:37 mforns: re-ran the Airflow DAG druid_load_unique_devices_per_project_family_daily for 2023-12-14
- 21:30 mforns: re-ran the Airflow DAG unique_devices_per_project_family_daily for 2023-12-14
- 21:29 mforns: re-ran the Airflow DAG unique_devices_per_domain_daily for 2023-12-14
- 21:26 mforns: re-ran Airflow job anomaly_detection_traffic_distribution_daily from 2023-12-14 to 2023-12-21
2023-12-21
[edit]- 15:36 btullis: creating superset and superset-next namespace on dse-k8s for T347710
2023-12-20
[edit]- 22:45 mforns: re-ran Airflow DAG druid_load_unique_devices_per_project_family_monthly for 2023-11
- 22:40 mforns: re-ran Airflow DAG druid_load_unique_devices_per_project_family_daily_aggregated_monthly for 2023-11
- 22:35 mforns: re-ran Airflow DAG druid_load_unique_devices_per_domain_monthly for 2023-11
- 22:28 mforns: re-ran Airflow DAG druid_load_unique_devices_per_domain_daily_aggregated_monthly for 2023-11
- 21:34 mforns: re-ran Airflow DAG cassandra_load_unique_devices_monthly for 2023-11
- 20:56 mforns: re-ran Airflow DAG cassandra_load_unique_devices_daily for 2023-11-08
- 20:27 mforns: re-ran Airflow DAG unique_devices_per_project_family_daily for 2023-11-08
- 20:26 mforns: re-ran Airflow DAG unique_devices_per_domain_daily for 2023-11-08
- 18:43 mforns: re-ran Airflow DAG unique_devices_per_domain_monthly for 2023-11
2023-12-19
[edit]- 22:23 mforns: reran Airflow dag unique_devices_per_project_family_monthly to fix MaxMind duplicate country name issue
- 21:50 mforns: cleared clickstream monthly sensors in Airflow since they failed waiting for data
- 21:44 mforns: deployed airflow wmde to unbreak their instance's config
- 21:44 mforns: deployed airflow analytics to modify unique devices dags
- 19:06 mforns: finished refinery deploy (weekly train)
- 18:30 xcollazo: Deploy latest DAG changes to Analytics Airflow instance
- 18:29 mforns: starting refinery deploy (weekly train)
- 11:10 btullis: restarted the jupyterhub-conda service on stat servers.
- 10:24 btullis: deploying version 0.0.27 of conda-analytics
2023-12-18
[edit]- 10:54 btullis: deploy conda-analytics v 0.0.27 to the hadoop-test-analytics cluster for T345482
- 09:43 btullis: cleared some space on an-test-worker1001 by deleting old refinery jars from /tmp `btullis@an-test-worker1001:/tmp$ sudo find . -type f -mtime +60 -name *.jar -delete`
- 09:22 btullis: deploying refinery version 0.02.27 to production refinery jobs with https://gerrit.wikimedia.org/r/c/operations/puppet/+/980923 for T349121
2023-12-15
[edit]- 13:53 brouberol: deploying spark-history-analytics-hadoop.spark-history.dse-k8s-eqiad.wmnet - T351816
- 12:55 brouberol: deploying spark-history-analytics-test-hadoop.spark-history-test.dse-k8s-eqiad.wmnet - T351816
2023-12-12
[edit]- 17:13 btullis: executed `apt clean` on an-coord1001 to free up 7GB.
2023-12-11
[edit]- 14:43 btullis: roll-restarting the aqs (nodejs based) services with https://gerrit.wikimedia.org/r/c/operations/puppet/+/982097
2023-12-07
[edit]- 21:45 xcollazo: Deployed latest changes to Airflow Analytics instance to pickup T352890
- 16:12 milimetric: finished deploying and syncing refinery
- 15:45 milimetric: deploying refinery for the sqoop fix
- 12:31 btullis: deploying conda-analytics v0.0.26 to hadoop-test
- 11:48 btullis: deploying refinery to hadoop-test only
2023-12-06
[edit]- 18:27 btullis: restarted hadoop-yarn-nodemanager and hadoop-hdfs-datanode services on an-worker1086 for T352168
- 17:19 btullis: deployed https://gerrit.wikimedia.org/r/c/operations/puppet/+/979118 for airflow metrice update to airflow_test instance for T349532
- 14:18 btullis: killed a stalled sqoop process on an-launcher1002
- 14:16 btullis: killed a stalled sqoop process on an-launcher1002
2023-12-05
[edit]- 15:21 btullis: I have pushed out version 0.0.25 of conda-analytics to the test cluster. No user facing changes expected.
- 08:29 stevemunene: depool druid10[04-06] T336043
2023-12-04
[edit]- 14:47 btullis: re-running refine_event for mediawiki_cirrussearch_request failure
- 14:42 btullis: restarted archiva service on archiva1002
- 14:38 btullis: cleared some space on -atest-worker1002 by running: `sudo find /tmp -type f -mtime +30 -delete`
- 13:53 btullis: bringing an-coord1003 into service as an `analytics_cluster::coordinator` for T336045
- 13:41 btullis: starting a rolling restart of the daemons on the analytics druid cluster, to make sure that they restart cleanly after the puppet 7 upgrade
- 12:14 stevemunene: pool druid1010 T336043
- 11:03 btullis: re-ran refine_eventlogging_analytics for MobileWikiAppiOSSessions
- 10:01 btullis: Marked TaskInstance: projectview_geo.move_data_to_archive scheduled__2023-12-02T04:00:00 as succeeded in airflow analytics.
2023-12-01
[edit]- 11:13 stevemunene: pool druid1010 after reimage T336043
- 10:04 btullis: marked TaskInstance: pageview_hourly.move_data_to_archive scheduled__2023-12-01T06:00:00+00:00 as succeeded in airflow analytics
2023-11-30
[edit]- 17:41 btullis: reran refine_event for mediawiki_cirrussearch_request
- 08:28 stevemunene: reimage druid1010 to pick up the right raid config and corresponding partman recipe T336043
2023-11-29
[edit]- 17:10 btullis: depool schema2004 for reimage to bookworm for T349286
- 17:07 btullis: pooled schema2003 after reimages a bookworm
- 15:30 btullis: depool schema2003 for upgrade to bookworm
- 15:24 btullis: pooled schema1004 after upgrade to bookworm for T349286
- 14:44 btullis: reimaging schema1004 to bookworm for T349286
- 14:43 btullis: depooling schema1004 for reimage T349286
- 14:41 btullis: pooled schema1003 after upgrade to bookeworm
- 14:10 btullis: reimaging schema1003 to bookworm for T349286
- 14:04 btullis: depooling schema1003 for reimage T349286
- 14:01 btullis: increased the size of the vg0/srv logical volume on an-web1001 by 350 GB for T349889
2023-11-28
[edit]- 18:30 milimetric: deployed refinery to hdfs
2023-11-27
[edit]- 21:03 btullis: deploying airflow-dags to analytics_test instance
- 15:05 stevemunene: pool druid1007 after bullseye reimage T332589
- 13:27 stevemunene: reimage druid1007 to upgrade to bullseye T332589
2023-11-24
[edit]- 12:34 joal: Rerun webrequest refine text for 2023-11-23T17
- 06:07 stevemunene: pool druid1008 after reimage T332589
2023-11-23
[edit]- 14:58 btullis: merging 974649: Remove all remaining references to oozie and clean up | https://gerrit.wikimedia.org/r/c/operations/puppet/+/974649 for T341893
- 14:12 btullis: roll-restarting hadoop masters on test cluster for T341893
- 12:44 btullis: removing oozie configuration from core hadoop files with https://gerrit.wikimedia.org/r/c/operations/puppet/+/974647 for T341893
- 11:05 gehel: testing SAL and logging
2023-11-22
[edit]- 16:27 joal: Kill duplicated XMLDumpsConverter
- 15:39 btullis: updating default airflow configuration with https://gerrit.wikimedia.org/r/c/operations/puppet/+/976700
- 12:22 btullis: applying security patches to postgres13 on an-db1001
2023-11-21
[edit]- 15:04 stevemunene: pool druid1011 after reimage T336043
2023-11-20
[edit]- 16:43 mforns: reran Airflow's refine_webrequest_hourly_text::refine_webrequest with excluded_row_ids for 2023-11-19T21
2023-11-19
[edit]- 08:15 mforns: reran Airflow's refine_webrequest_hourly_text::refine_webrequest with excluded_row_ids for 2023-11-19T00
2023-11-18
[edit]- 21:57 mforns: eran Airflow's refine_webrequest_hourly_text::refine_webrequest with excluded_row_ids for 2023-11-18T12
- 19:47 mforns: reran Airflow's refine_webrequest_hourly_text::refine_webrequest with excluded_row_ids for 2023-11-17T22
2023-11-17
[edit]- 14:58 mforns: marked several failed tasks of datahub_ingestion DAG in Airflow, because the issues were fixed, added notes to the DAG itself
- 12:55 joal: Rerun Airflow metadata_ingest_daily datahub job
2023-11-16
[edit]- 14:45 btullis: rolling out 974993: Add spark.sql.warehouse.dir to spark3 defaults | https://gerrit.wikimedia.org/r/c/operations/puppet/+/974993 for T349523
- 13:22 sergi0: stat1008: Add `sowiki`, `stwiki`, `tgwiki` and `ugwiki` to `/srv/published/datasets/one-off/research-mwaddlink/wikis.txt` (T340944)
2023-11-15
[edit]- 20:44 xcollazo: Ran 'sudo -u analytics hdfs dfs -rm -r -skipTrash /user/hive/warehouse/wmf_dumps.db/wikitext_raw_rc1' to delete HDFS data of old release candidate table
- 20:43 xcollazo: Ran 'sudo -u analytics hdfs dfs -rm -r -skipTrash /wmf/data/wmf_dumps/wikitext_raw_rc0' to delete HDFS data of old release candidate table
- 20:42 xcollazo: Ran 'DROP TABLE wmf_dumps.wikitext_raw_rc0' and 'DROP TABLE wmf_dumps.wikitext_raw_rc1' to delete older release candidate tables.
- 14:51 ottomata: deployed refine using refinery-job 0.2.26 JsonSchemaConverter from wikimedia-event-utilities - https://phabricator.wikimedia.org/T321854
- 14:33 joal: Deploy refinery onto HDFS (unique-devices hotfix)
- 13:44 joal: Deploying refinery for unique-devices hotfix
- 11:22 btullis: exiting safe mode
- 11:06 btullis: merged all config files changes replacing an-coord1001 with an-mariadb1001
- 11:04 btullis: position confirmed, resetting all slaves on an-mariadb1001 for T284150
- 11:02 btullis: set an-coord1001 mysql to read_only
- 11:01 btullis: entering HDFS safe mode
- 11:01 btullis: proceeding with the implementation plan here: https://phabricator.wikimedia.org/T284150#9330525
- 10:43 btullis: temporarily disabled production jobs that write to HDFS
2023-11-14
[edit]- 20:35 sfaci: recreated unique_devices iceberg tables
- 20:35 sfaci: restarted Druid supervisors
- 19:55 sfaci: Deployed refinery using scap, then deployed onto hdfs
- 19:24 sfaci: Deploying refinery using scap
- 14:50 btullis: roll-restarting the presto cluster to pick up new puppet 7 CA settings
- 14:28 btullis: performing a rolling restart of the mariadb services on dbstore100[3,5,7] post this patch: https://gerrit.wikimedia.org/r/c/operations/puppet/+/968668
- 11:03 stevemunene: depool druid100[4-6] set pooled=inactive
2023-11-13
[edit]- 23:34 btullis: rebooting clouddb1021 to pick up new kernel and puppet 7 CA.
- 21:28 btullis: deploying updated datahub containers for T348647
- 21:27 btullis: reloading haproxy on dbproxy1018 post maintenance
- 17:07 ottomata: deploying refinery with refinery source 0.2.25 jars and using 0.2.25 for refine job - T321854
- 13:57 btullis: reloaded haproxy on dbproxy1018 to depool the analytics wikireplicas cluster
- 12:31 btullis: repooled clouddb10[13-16] post maintenance.
- 11:08 btullis: rebooting clouddb1013 to pick up new kernel and SSL CA settings
- 10:49 btullis: systemctl reload haproxy on dbproxy1019 to depool the web wikireplica cluster
2023-11-09
[edit]- 14:43 btullis: pooled druid10[09-11] in the druid-public cluster.
- 12:29 btullis: Proceeding to roll-restart yarn nodemanagers with `sudo cumin A:hadoop-worker -b 1 -s 30 'systemctl restart hadoop-yarn-nodemanager.service'` for T344910
- 11:47 btullis: restarting yarn-nodemanager service on an-worker1100.eqiad.wmnet as a canary for T344910
- 11:14 btullis: deploying multiple spark shufflers to production for T344910
- 09:53 btullis: executed `helmfile -e eqiad --state-values-set roll_restart=1 sync` to roll-restart datahub in eqiad
- 09:43 btullis: executed `helmfile -e codfw --state-values-set roll_restart=1 sync` to roll-restart datahub in codfw
2023-11-08
[edit]- 15:52 stevemunene: Add analytics-wmde service user to the Yarn production queue T340648
- 13:55 btullis: beginning rolling restart of all hadoop workers in production, to pick up new puppet 7 CA settings.
- 10:33 btullis: restarting hadoop-hdfs-datanode.service and hadoop-yarn-nodemanager.service on an-worker1111 to pick up puppet7 changes.
- 10:27 brouberol: running scap deploy for airflow-dags/analytics
2023-11-07
[edit]- 20:48 xcollazo: Ran 'kerberos-run-command hdfs hdfs dfs -chmod -R g+w /wmf/data/wmf_dumps/wikitext_raw_rc2' to ease experimentation on this release candidate table.
- 15:52 btullis: restart airflow-sheduler and airflow-webserver services on an-test-client1002
- 15:50 btullis: restart mariadb service on an-test-coord1001
- 15:50 btullis: restart mariadb service on an-test-coord100
- 15:49 btullis: restart presto-server service on an-test-coord1001 and an-test-presto1001 to pick up new puppet 7 CA settings
- 15:48 btullis: restart hive-server2 and hive-metastore services on an-test-coord1001 to pick up new puppet 7 CA settings.
- 15:35 btullis: roll-restarting hadoop workers in test, to test new puppet 7 CA settings.
- 14:52 btullis: roll-restarting hadoop masters on the test cluster, after upgrading to puppet 7
- 12:05 btullis: deploying datahub to prod for the pki certificates.
- 11:36 btullis: deploying datahub to staging to start using pki certificates - https://gerrit.wikimedia.org/r/c/operations/deployment-charts/+/969345/
- 10:40 btullis: re-running the kafka_jumbo_ingestion in analytics airflow
2023-11-06
[edit]- 18:38 milimetric: deployed refinery-source, starting to deploy analytics airflow dags
- 13:57 stevemunene: roll-restart druid public workers to pick up a new zookeeper node druid1009. T336042
- 13:32 stevemunene: restart zookeper leader to pick up new host druid1009 T336042
- 13:25 stevemunene: stop and disable zookeper on druid1004 T336042
- 13:19 stevemunene: disable puppet on druid1004 and druid10[09-11] to Onboard new druid1009 to the ZooKeeper cluster for `druid-public-eqiad` cluster
2023-11-01
[edit]- 15:58 stevemunene: powercyle stat1008, host is frozen/stuck in an unresponsive state
2023-10-31
[edit]- 09:26 brouberol: I replaced the self-signed skein certificate by one issued by our cfssl PKI on an-test1002 - T329398
2023-10-26
[edit]- 16:18 stevemunene: roll-restart druid public workers to pick up new zookeeper hosts. T336042
- 15:29 stevemunene: stop zookeper on druid1005 current leader for the `druid-public-eqiad` this will trigger the election of a new leader T336042
- 10:18 stevemunene: restart zookeper leader to pick up new host druid1011 T336042
- 09:18 stevemunene: stop zookeper on druid1006 T336042
- 08:48 brouberol: sudo cookbook sre.hosts.reimage --os bullseye -t T348495 kafka-jumbo1009
- 08:06 brouberol: sudo cookbook sre.hosts.reimage --os bullseye -t T348495 kafka-jumbo1008
2023-10-24
[edit]- 16:46 xcollazo: Deploying latest DAGs to analytics Airflow instance
- 12:41 joal: Drop wmf.referrer_daily hive table and data
- 10:07 btullis: transferring snapshot s2.2023-10-23--01-34-18 from dbprov1004 to dbstore1007:/srv/sqldata.s2
- 10:02 btullis: stopping and deleting s2 on dbstore1007.
2023-10-23
[edit]- 10:14 brouberol: sudo cookbook sre.hosts.decommission -t T336044 kafka-jumbo1001.eqiad.wmnet
- 10:11 btullis: deploying multiple spark shufflers to the test cluster for T344910
- 09:58 brouberol: sudo cookbook sre.hosts.decommission -t T336044 kafka-jumbo1002.eqiad.wmnet
- 09:47 btullis: restarting krb5-kdc.service and krb5-admin-server.service on krb1001 and re-enabling puppet for T346135
- 09:10 btullis: root@krb1001:~# systemctl stop krb5-kdc.service krb5-admin-server.service
- 09:09 btullis: disabling puppet on krb1001 for T346135
- 08:53 brouberol: sudo cookbook sre.hosts.decommission -t T336044 kafka-jumbo1004.eqiad.wmnet
- 08:28 brouberol: sudo cookbook sre.hosts.decommission -t T336044 kafka-jumbo1005.eqiad.wmnet - T336044
2023-10-19
[edit]- 19:58 xcollazo: ran "sudo -u hdfs hdfs dfs -cp /user/xcollazo/artifacts/spark-3.3.2-assembly.zip /user/spark/share/lib/" and "sudo -u hdfs hdfs dfs -chmod o+r /user/spark/share/lib/spark-3.3.2-assembly.zip" to bring make Spark 3.3.2 assembly available for other folks.
- 19:54 xcollazo: ran "sudo -u hdfs hdfs dfs -rm /user/spark/share/lib/spark-3.1.2-assembly.jar.backup" to remove old spark assembly backup from May 25 2023.
- 19:52 xcollazo: ran "$ sudo -u hdfs hdfs dfs -rm /user/spark/share/lib/spark-3.1.2-assembly.jar.bak" to remove old spark assembly backup from Jun 13 2023.
- 15:22 brouberol: The kafka service has been stopped on kafka-jumbo100[1-6] - T336044
- 15:04 brouberol: sudo cumin --batch-size 1 --batch-sleep 60 'kafka-jumbo100[1-6].eqiad.wmnet' 'sudo systemctl stop kafka.service' - T336044
- 15:02 brouberol: disabling puppet on kafka-jumbo100[1-6] to make sure kafka isn't resarted - T336044
- 12:13 brouberol: disabling puppet on kafka-jumbo nodes so we can merge https://gerrit.wikimedia.org/r/c/operations/puppet/+/966497
- 09:42 btullis: re-running airflow jobs for missing webrequest data on hadoop-test
2023-10-18
[edit]- 18:03 stevemunene: revert Add analytics-wmde service user to the Yarn production queue T340648
- 17:43 tchin: deploying mw-page-content-change-enrich
- 16:53 stevemunene: Add analytics-wmde service user to the Yarn production queue T340648
- 09:14 btullis: rebooting stat100[6-7]
- 09:07 btullis: rebooting stat1004
- 07:01 aqu: Started deploy [airflow-dags/analytics@5dcce3b]: Add missing MR in yesterday weekly train
2023-10-17
[edit]- 16:17 btullis: restarting hadoop-yarn-nodemanager on an-test-worker1001
- 14:01 tchin: deploying airflow analytics
- 13:39 tchin: deploying refinery
- 12:56 btullis: deploying multiple spark shufflers to the test cluster
- 09:51 btullis: re-enabling all previously paused dags
- 09:50 btullis: restarting all airflow schedulers after rebooting an-db1001
- 09:10 btullis: pausing both active dags on the analytics_product airflow instance
- 09:09 btullis: pausing all 7 active dags on airflow-platform_eng airflow instance
- 09:07 btullis: pausing all 3 active dags on airflow-research instance
- 09:07 btullis: pausing all 28 active airflow dags on airflow-search instance
- 09:03 btullis: pausing all airflow dags on analytics instance
2023-10-16
[edit]- 13:05 brouberol: deploying mw-page-content-change-enrich with the new kafka broker list T336044
- 10:06 btullis: deploying presto version 0.283 to production for T342343 with `sudo debdeploy deploy -u 2023-10-12-presto.yaml -Q 'P{O:analytics_cluster::presto::server} or P{O:analytics_cluster::coordinator} or A:stat'`
- 08:49 brouberol: redeploying datahub with the new kafka broker list T336044
- 08:42 brouberol: redeploying eventgate-analytics-external with the new kafka broker list T336044
- 08:38 brouberol: redeploying eventgate-analytics with the new kafka broker list T336044
- 08:34 brouberol: redeploying eventstreams-internal with the new kafka broker list T336044
2023-10-12
[edit]- 13:22 btullis: rebooting archiva1002.wikimedia.org for T344671
- 12:00 btullis: pushing out presto version 0.283 to the test cluster.
- 09:31 btullis: rebooting an-coord1002 for T344671
- 09:18 btullis: power cycling an-master1002 to address unresponsiveness
2023-10-11
[edit]- 09:27 btullis: trigger rolling-restart of aqs services with `sudo cumin -b 2 -s 20 A:aqs 'systemctl restart aqs'`
2023-10-09
[edit]- 18:35 mforns: deployed airflow analytics
- 10:46 btullis: started rolling restart of an-worker1[078-156] for T344587
- 08:55 btullis: started rolling restart of analytics10[70-77] for T344587
2023-10-05
[edit]- 15:30 btullis: failed over test cluster hadoop namenode services to an-test-master1002
2023-10-04
[edit]- 06:19 Surbhi_: Deployed refinery using scap, then deployed onto hdfs
2023-10-02
[edit]- 16:45 joal: Silent the "High Kafka consumer lag for mw_page_content_change_enrich in codfw" alert for 3 days
- 13:40 stevemunene: roll-restart druid public workers to pick up a new worker node. T336042
- 13:28 joal: Manually mark wikidata_item_page_link_weekly.wait_for_mediawiki_page_move task successfull (with note) to overcome datacenter switchover sensor issue
- 13:27 joal: Manually mark wikidata_item_page_link_weeklywait_for_mediawiki_page_move
- 07:36 joal: deploying mw-page-content-change-enrich on codfw after kafka has finished synchronizing its replicas
2023-09-29
[edit]- 13:10 btullis: systemctl reset-failed on kafka-mirror-main-eqiad_to_jumbo-eqiad@0.service on kafka-jumbo1001
- 12:07 joal: mw_page_content_change_enrich alert silenced for the weekend, the app is down, more investigation next week
- 12:06 joal: Various restarts of mw_page_content_change_enrich k8s app since yesterday - the app is failing to send data to kafka
2023-09-28
[edit]- 16:38 btullis: rebooting eventlog1003 for T344671
- 15:50 btullis: failed back namenode services from an-master1002 to an-master1001
- 13:57 brouberol: started the evacuation of a subset of topics away from kafka-10[01-06].eqiad.wmnet T336044
- 10:56 btullis: sudo systemctl start hadoop-hdfs-namenode.service on an-master1001 after cookbook failback failure
- 10:27 btullis: roll-restarting hadoop namenodes to pick up new heap settings.
2023-09-27
[edit]- 14:56 xcollazo: Deploy latest Airflow DAGs to analytics instance
- 14:14 btullis: removing downtime for kafka-jumbo
- 14:12 btullis: re-enabled and run puppet on the rest of kafka-jumbo to bring the mirror-makers back to where they should be.
- 14:07 btullis: deploying kafka-mirror-maker exclusion patch to kafka-jumbo100[1-6]
- 13:44 aqu: Deployed refinery using scap, then deployed onto hdfs
- 13:12 aqu: Deployment weekly train of analytics-refinery (included new refinery-source version)
- 12:18 btullis: added 3 more hours downtime to kafka-jumbo101[0-5].eqiad.wmnet
- 08:29 elukey: `elukey@cumin1001:~$ sudo cumin 'kafka-jumbo10[01-05]*' 'systemctl start kafka-mirror' -b 1 -s 30`
- 08:28 elukey: `elukey@cumin1001:~$ sudo cumin 'kafka-jumbo10[06-15]*' 'systemctl stop kafka-mirror'`
- 08:13 elukey: slowly start mirror maker on one instance at the time on all jumbo nodes
- 08:11 elukey: start kafka mirror on jumbo1002
- 08:08 elukey: stop all mirror maker on jumbo, start only one on jumbo1001
- 07:47 elukey: roll restart mirror maker instances on kafka jumbo
2023-09-26
[edit]- 10:43 btullis: deploying conda-analytics v0.0.23 to stats servers for T337258
- 10:36 btullis: deploying conda-analytics v0.0.23 to analytics-airflow for T337258
- 10:34 btullis: deploying conda-analytics v0.0.23 to hadoop-all for T337258
- 10:28 btullis: upgrading outdated bigtop packages on stat1009 with `dpkg -l |egrep "\-deb11"|awk '{print $2}'|xargs sudo apt install` for T337465
- 10:11 btullis: running 'dpkg -l |egrep "\-deb11"|awk '{print $2}'|xargs sudo apt install` on an-test-client1002 for T337465
- 09:24 btullis: pushing out build 0.0.23 of conda-analytics to hadoop-test.
2023-09-25
[edit]- 08:53 btullis: `root@archiva1002:/var/cache/archiva# sudo rm -rf temp*`
2023-09-24
[edit]- 18:35 btullis: restarted archiva to see if it clears some temp files.
2023-09-21
[edit]- 17:59 xcollazo: Deploy latest DAGs to analytics Airflow instance
- 15:02 milimetric: deployed aqs 1.0 to enable etags on all endpoints - so far everything looks ok
- 08:56 joal: Rerun edit-hourly druid indexation to fix corrupted data file
- 08:10 brouberol: redeploying eventgate-analytics in staging T336041
2023-09-19
[edit]- 14:19 jennifer_ebe: airflow analytics deployment with scap successful
- 13:57 btullis: pushing out https://gerrit.wikimedia.org/r/c/operations/puppet/+/955893 for new refinery job jar files
- 13:43 jennifer_ebe: deploying airflow analytics dag
- 13:32 jennifer_ebe: deployment successful
- 13:07 jennifer_ebe: redeploying refinery from deployment.eqiad.wmnet using scap
- 12:02 jennifer_ebe: deploying refinery from deployment.eqiad.wmnet
- 09:40 btullis: commencing rolling restart of all brokers in kafka-jumbo
- 09:27 btullis: deploying change to kafka-jumbo settings for T344688
- 08:17 brouberol: redeploying eventstream-analytics in eqiad T336041
- 08:05 brouberol: redeploying eventstream-internal in staging T336041
- 08:02 brouberol: redeploying eventgate-analytics-external in staging T336041
- 07:59 brouberol: redeploying eventgate-analytics in staging T336041
2023-09-18
[edit]- 15:38 btullis: deploying Superset 2.1.1 to an-tool1005 for superset-next.wikimedia.org
- 13:14 brouberol: Puppet run successfully on kafka-jumbo1010.eqiad.wmnet. The kafka service is running. T336041
- 10:45 stevemunene: deploy datahub in eqiad to pick up new changes T305874
- 10:42 stevemunene: deploy datahub in codfw to pick up new changes T305874
- 09:51 stevemunene: disable auth_jaas and native login to datahub then enable oidc authentication to production in eqiad T305874
- 09:43 stevemunene: disable auth_jaas and native login to datahub then enable oidc authentication to production in codfw T305874
2023-09-14
[edit]- 21:40 btullis: executed apt-get clean on hadoop-test
- 21:31 btullis: deploying conda-analytics version 0.0.21 to hadoop-test for T337258
- 18:28 xcollazo: Deployed latest DAGs to analytics Airflow instance T340861
- 14:13 stevemunene: powercycle an-worker1138, investigating failures related to reimage T332570
- 11:42 btullis: deploying conda-analytics version 0.0.20 to the test cluster for T337258
2023-09-12
[edit]- 14:59 btullis: successfully failed back the HDFS namenode services to an-master1001
- 11:21 btullis: demonstrated the use of SAL for T343762
- 09:54 btullis: btullis@an-master1001:~$ sudo -u hdfs /usr/bin/hdfs haadmin -failover an-master1002-eqiad-wmnet an-master1001-eqiad-wmnet
2023-09-07
[edit]- 16:55 btullis: restarting the aqs service on all aqs* servers in batches to pick up new MW_history snapshot.
- 13:43 mforns: (actual timestamp: 2023-09-06, 19:10:29 UTC) cleared airflow task mediawiki_history_reduced.check_mediawiki_history_reduced_error_folder (and subsequent tasks) for snapshot=2023-08. This was due to false positive errors having been generated by the checker.
2023-09-05
[edit]- 14:26 btullis: completed eventstreams and eventstreams-internal deployments.
- 14:23 btullis: deploying eventstreams for T344688
- 14:15 btullis: deploying eventstreams-internal for T344688
- 12:35 stevemunene: power cycle an-worker1132. Host is stuck on debian install after a failed reimage.
- 10:35 joal: Rerun cassandra_load_pageview_top_articles_monthly
- 10:35 joal: Clear airflow false-failed tasks for pageview_hourly (log-aggregation issue)
2023-09-01
[edit]- 07:43 stevemunene: powercycle an-worker1145.eqiad.wmnet host cpus soft lockup T345413
2023-08-31
[edit]- 13:02 aqu: Deployed refinery using scap, then deployed onto hdfs
- 12:01 aqu: About to deploy analytics refinery (weekly train)
2023-08-30
[edit]- 15:43 stevemunene: restart hadoop-yarn-nodemanager.service on an-worker11[29-48].eqiad.wmnet in batches of 2 with 3 minutes in between
- 14:46 stevemunene: restart hadoop-yarn-nodemanager.service on an-worker11[00-28].eqiad.wmnet in batches of 2 with 3 minutes in between
- 14:08 stevemunene: restart hadoop-yarn-nodemanager.service on an-worker10[78-99].eqiad.wmnet in batches of 2 with 3 minutes in between
- 12:41 stevemunene: disable puppet on an-worket1147 test hadoop-yarn log aggregation compression algorithm The compression was set to gzip but should have been set to gz
- 12:26 stevemunene: restart hadoop-yarn-nodemanager.service on an-worker1147
2023-08-29
[edit]- 11:01 joal: Update mediawiki_history_check_denormalize airflow job variables to send job-reports to both data-engineering-alerts and product-analytics
- 10:52 joal: Deploy airflow-dags/analytics
2023-08-24
[edit]- 18:20 btullis: attempting another failback of the hadoop namenode services
- 16:47 btullis: start hadoop namenode on an-master1001 after crash.
- 16:46 btullis: failback unsuccessful. namenode services still running on an-master1002.
- 16:43 btullis: going for failback of HDFS namenode service from an-master1002 to an-master1001
- 16:10 btullis: about to reboot an-master1001
- 16:09 btullis: failing over yarn resourcemanager to an-master1002
- 16:07 btullis: failing over hdfs namenode from an-master1001 to an-master1002
- 12:40 btullis: rebooting an-coord1001
- 12:08 btullis: failing over hive to an-coord1002 in advance of reboot of an-coord1001
- 11:24 btullis: btullis@cp3074:~$ sudo systemctl start varnishkafka-webrequest.service
2023-08-23
[edit]- 14:50 btullis: rebooting an-launcher1002
- 08:22 btullis: beginning a rolling reboot of kafka-jumbo
2023-08-22
[edit]- 17:24 joal: Redeploying refinery onto Hadoop-test to try to fix jar issue
- 14:29 gmodena: deploying refinery with hdfs
- 14:08 gmodena: deploying refinery using scap
- 13:03 btullis: deploying the change to the yarn log retention and compression for T342923
2023-08-17
[edit]- 15:12 btullis: failing hive back to an-coord1001 following maintenance
- 14:59 btullis: restarting hive-server2 and hive-metastore services on an-coord1001 after failover.
- 14:49 btullis: failing over hive to an-coord1002 to permit restart of hive on an-coord1001
- 09:29 btullis: deploying airflow-analytics
2023-08-16
[edit]- 17:06 btullis: aqs deploy completed successfully.
- 17:05 btullis: re-ran efine_eventlogging_analytics failed job and sent follow-up email.
- 16:52 btullis: deploying aqs again
- 16:43 btullis: deploying aqs
2023-08-14
[edit]- 09:27 btullis: rebooted an-worker1124 due to CPU lockups
2023-08-12
[edit]- 14:16 btullis: re-ran refine_event job for 'mediawiki_revision_create|mediawiki_page_create'
2023-08-10
[edit]- 16:59 btullis: re-enabled airflow jobs on analytics_test instance
- 08:58 btullis: rebooting an-db1001
- 08:57 btullis: stopped all airflow-scheduler services
- 08:57 btullis: paused all dags on all airflow instances
2023-08-09
[edit]- 14:22 btullis: failing over namenode on test cluster from an-test-master1001 to an-test-master1002 after upgrade of an-test-master1002 to bullseye
- 11:31 btullis: I did systemctl reset-failed logrotate.service on datahubsearch1002
- 11:08 btullis: starting hadoop-hdfs-namenode.service on an-master1002
- 11:02 btullis: failing over namenode services to an-master1002 so that I can reboot an-master1001
- 09:49 btullis: restarted systemd-timedate service on an-worker1086
2023-08-07
[edit]- 17:09 btullis: deploying new mediawiki_history snapshot to AQS
2023-08-02
[edit]- 20:42 xcollazo: deployed latest for Airflow analytics instance.
- 19:30 xcollazo: deploying refinery to try and fix https://lists.wikimedia.org/hyperkitty/list/data-engineering-alerts@lists.wikimedia.org/thread/QKXYMYKMWXGRNYZ77CENA5F2EGA66QQ2/
- 12:42 xcollazo: Redeploy of analytics_product Airflow instance to see it it clears a Spark issue
2023-08-01
[edit]- 11:37 btullis: ran apt clean on an-tool1009 to free up disk space
- 06:24 elukey: roll restart kafka jumbo brokers to apply new threads settings
2023-07-31
[edit]- 19:03 xcollazo: Deployed https://gitlab.wikimedia.org/repos/data-engineering/airflow-dags/-/merge_requests/471 for analytics Airflow instance
- 12:25 btullis: upgrading airflow on an-launcher1002 to 2.6.3
2023-07-28
[edit]- 19:38 xcollazo: Deployed T342926 and https://gitlab.wikimedia.org/repos/data-engineering/airflow-dags/-/merge_requests/469 to analytics Airflow instance
- 14:34 milimetric: deployed a fix for a sqoop typo
2023-07-27
[edit]- 18:48 milimetric: done deploying some simple stuff to refinery (static files and script comment updates)
2023-07-25
[edit]- 09:42 stevemunene: powercycle wdqs1013.eqiad.wmnet
2023-07-19
[edit]- 16:35 joal: Deploy airflow fixfor cassandra loading jobs
- 13:44 btullis: restarting hive-server2 and hive-metastore services on an-coord1001 (currently standby)
- 12:38 joal: deploy Airflow analytics dags - Fullrevampof cassandraloading jobs
- 11:22 jennifer_ebe: deploying refinery to hdfs
- 10:57 jennifer_ebe: deploying refinery using scap
- 10:54 btullis: migrating hive services to an-coord1002 via DNS for T329716 (to permit restart of hive services on an-coord1001).
- 10:15 btullis: restarting oozie service on an-coord1001 for T329716
- 10:14 btullis: restarting presto-service on an-coord1001 for T329716
- 10:06 btullis: restarting java services on an-test-coord1001 for JVM update
- 09:13 btullis: correction: to an-test-client1002
- 09:13 btullis: deploying airflow-dags for analytics_test to an-test-client1001
2023-07-18
[edit]- 13:20 stevemunene: deploy airflow-dags to an-test-client1002 T341700
2023-07-17
[edit]- 13:34 elukey: `kill `pgrep -u appledora`` and `kill `pgrep -u akhatun`` on stat1008 to unblock puppet (offboarded users deletion)
- 13:32 btullis: proceeding to reimage analytics1072 (journalnode, in addition to datanode)
- 09:31 btullis: restarted airflow services on an-test-client1002 in order to pick up new versions
- 09:20 btullis: upgrading airflow on an-test-client1002 to version 2.6.3
2023-07-13
[edit]- 20:38 xcollazo: deployed Airflow DAGs for analytics instance to pickup T335860
2023-07-12
[edit]- 16:26 btullis: `sudo cumin A:wikireplicas-all 'maintain-views --replace-all --all-databases --table revision'` for T339037
- 14:11 btullis: roll-restarting zookeeper on druid-public for new JVM version
2023-07-11
[edit]- 11:00 btullis: Proceeding to upgrade datahub in production
- 08:59 btullis: rebooting kafkamon1003
- 08:54 btullis: `systemctl start burrow-jumbo-eqiad.service` on kafkamon1003 for T341551
2023-07-10
[edit]- 14:04 btullis: powered on an-worker1145
- 14:02 btullis: powered off an-worker1145 for T341481
- 10:55 btullis: `sudo -u hdfs /usr/bin/hdfs haadmin -failover an-master1002-eqiad-wmnet an-master1001-eqiad-wmnet` on an-master1001
2023-07-07
[edit]- 09:56 btullis: `sudo systemctl start hadoop-hdfs-namenode.service ` on an-master1001
- 09:28 stevemunene: running sre.hadoop.roll-restart-masters restart the maters to completely remove any reference of analytics[1058-1069] T317861
- 09:15 stevemunene: run puppet on hadoop masters to pick up changes from recently decommissioned hosts
- 08:12 elukey: wipe kafka-test cluster (data + zookeper config) to start clean after the issue happened yesterday
2023-07-06
[edit]- 14:51 elukey: upgraded zookeeper-test1002 to bookworm, but its metadata got re-initialized as well (my bad for this)
- 14:30 stevemunene: decommission analytics1069.eqiad.wmnet T341209
- 14:19 stevemunene: decommission analytics1068.eqiad.wmnet T341208
- 14:06 stevemunene: decommission analytics1067.eqiad.wmnet T341207
- 13:13 stevemunene: decommission analytics1066.eqiad.wmnet T341206
- 13:02 stevemunene: decommission analytics1065.eqiad.wmnet T341205
- 12:35 stevemunene: decommission analytics1064.eqiad.wmnet T341204
- 11:18 stevemunene: decommission analytics1063.eqiad.wmnet T339201
- 10:40 stevemunene: decommission analytics1062.eqiad.wmnet T339200
- 09:57 stevemunene: decommission analytics1061.eqiad.wmnet T339199
- 07:23 stevemunene: run puppet agent on hadoop masters
- 07:21 stevemunene: Remove analytics1064_1069 from hdfs net_topology
- 07:18 stevemunene: stop hadoop-hdfs-datanode service on analytics[1061-1069] Preparing to decommission the hosts - T317861
- 07:11 stevemunene: disable-puppet on analytics[1061-1069] Preparing to decommission the hosts - T317861
2023-07-05
[edit]- 14:36 stevemunene: enable puppet on analytics1069 to get the host back into puppetdb and hence allow the the decommission cookbook run later
- 11:47 btullis: restarted archiva for T329716
- 11:45 btullis: restarted hive-servers2 and hive-metastore service on an-coord1002
- 11:40 btullis: roll-restarting kafka-jumbo brokers for T329716
- 11:01 btullis: roll-restarting the presto workers for T329716
- 10:20 btullis: deploying updated spark3 defaults to disable the `spark.shuffle.useOldFetchProtocol`option for T332765
- 09:45 btullis: failing back namenode to an-master1001 with `sudo -u hdfs /usr/bin/hdfs haadmin -failover an-master1002-eqiad-wmnet an-master1001-eqiad-wmnet` on an-master1001
- 09:38 btullis: re-enabled gobblin jobs on an-launcher1002
- 09:03 btullis: switching yarn shuffler - running puppet on 87 worker nodes
- 08:44 btullis: disabled gobblin and spark jobs on an-launcher for T332765
- 08:33 btullis: disabled gobblin jobs with https://gerrit.wikimedia.org/r/c/operations/puppet/+/935425
- 08:27 btullis: roll-restarting hadoop workers in the test cluster
2023-07-04
[edit]- 13:55 btullis: roll-restarting the eventgate-analytics-external worker pods in eqiad with: `helmfile -e eqiad --state-values-set roll_restart=1 sync`
- 10:31 btullis: beginning hdfs datanode rolling restart with `sudo cumin -b 2 -p 80 -s 120 A:hadoop-worker 'systemctl restart hadoop-hdfs-datanode'`
- 10:10 btullis: btullis@an-master1001:~$ sudo systemctl start hadoop-hdfs-namenode
- 10:00 btullis: roll-restarting journal nodes with 30 seconds between each one: `sudo cumin -b 1 -p 100 -s 30 A:hadoop-hdfs-journal 'systemctl restart hadoop-hdfs-journalnode'`
- 09:29 btullis: restarting the yarn restart with `sudo cumin -b 5 -p 80 -s 30 A:hadoop-worker 'systemctl restart hadoop-yarn-nodemanager'`
- 08:57 btullis: executing `cookbook sre.hadoop.roll-restart-workers analytics`
2023-07-03
[edit]- 12:52 btullis: restarting the aqs service to pick up mediawiki history snapshot for June
2023-06-29
[edit]- 13:44 btullis: upgrading airflow on an-launcher1002 to version 2.6.1
2023-06-28
[edit]- 13:25 btullis: upgrading an-test-worker1003 to bullseye, after upgrading firmware
- 13:08 btullis: upgrading idrac firmware of an-test-worker1003 via the cookbook for T329363
2023-06-27
[edit]- 14:53 mforns: deployed airflow analytics to unbreak DataHub's Druid ingestion
- 13:32 joal: Rerun druid_load_pageviews_hourly_aggregated_daily after deploy
- 13:32 joal: druid_load_pageviews_hourly_aggregated_dailyRerun
- 13:25 joal: Deploy Airflow
- 11:10 joal: Deploy refinery onto HDFS
- 11:01 stevemunene: upgrading an-test-worker1003 to bullseye, keeping `/srv/hadoop` intact
- 10:55 joal: Deploy refinery using scap
- 09:42 stevemunene: !log run puppet on hadoop-masters this does a refresh of the hdfs nodes
- 09:38 stevemunene: Exclude analytics1061_1069 from HDFS and YARN
- 09:21 btullis: upgrading an-test-worker1002 to bullseye, keeping `/srv/hadoop` intact
- 08:38 elukey: revoked puppet cert for 'varnishkafka' and cleaned up its cergen's files in puppet private
- 07:14 elukey: `sudo kill `pgrep -u paramd`` on stat1005 to unblock puppet
2023-06-26
[edit]- 23:22 btullis: shutting down an-worker1092 in preparation for RAID controller battery replacement
- 14:06 elukey: move varnishkafka instances in esams to pki - T337825
- 11:39 stevemunene: running hdfs dfsadmin -refreshNodes to pick up analytics106[1-3] from hosts.exclude
- 11:35 stevemunene: disable puppet on an-master1001.eqiad.wmnet
- 09:40 joal: Rerun failed druid-loading airflow jobs
- 09:38 btullis: deploying presto version 0.281 to production
- 06:28 stevemunene: run puppet on hadoop-masters
- 06:27 stevemunene: Excluding analytics106[4-6] from HDFS and YARN as we Decommission them
2023-06-23
[edit]- 12:40 elukey: move varnishkafka drmrs instances to pki - T337825
- 10:20 btullis: reboot an-worker1110 after initializing a second replacement drive for T336929
- 10:16 elukey: restart turnilo to pick up config changes - T340097
2023-06-22
[edit]- 15:57 btullis: adding new bigtop-1.5 packages to apt.wikimedia.org for bullseye
- 15:50 elukey: update the webrequest_sampled_live druid kafka supervisor to add the https field - T340097
- 15:18 btullis: cleared status for aqs_hourly.wait_for_webrequest run 13:00 and the downstream task on an-test-client1001.
- 15:07 btullis: clearing task for refine_webrequest_hourly_test_text hour 13:00
- 14:36 btullis: restarted airflow-webserver and airflow-scheduler on an-test-client1001 with version 2.6.1.
- 14:11 btullis: redeploying datahub to staging to try to get upgrade to 0.10.0 working.
- 14:02 stevemunene: running sre.hadoop.roll-restart-masters restart the Namenodes to completely remove any reference of analytics106[1-3] T317861
- 13:47 stevemunene: run puppet on hadoop-masters
- 13:43 stevemunene: Remove analytics106[1-3] from the HDFS topology
- 13:16 elukey: move varnishafka instances in eqiad to PKI - T337825
- 13:14 btullis: deploying the new eventgate-wikimedia container to eventgate-main
- 08:57 btullis: cleared airflow task for `projectview_geo.move_data_to_archive`
2023-06-21
[edit]- 16:46 joal: Rerun cassandra-load tasks for pageview-per-project daily and hourly for 2023-06-20 hour 4
- 16:46 joal: rerun browser_general_daily for 2023-06-20
- 16:40 joal: Rerun projectview-hourly DAG for hour: 2023-06-20T04:00
- 15:44 mforns: deployed airflow analytics to remove deprecated dag for mobile_apps
- 12:51 elukey: move varnishafka instances in codfw to PKI - T337825
2023-06-20
[edit]- 21:28 aqu: Manual edit of `/srv/airflow-analytics/connections.yml` following changes in https://gerrit.wikimedia.org/r/c/operations/puppet/+/931690 to avoid alerts Airflow analytics aqs_hourly
- 20:59 aqu: Manually marked as success `wikidata_dump_to_hive_weekly` iteration `2023-02-13` in Airflow analytics
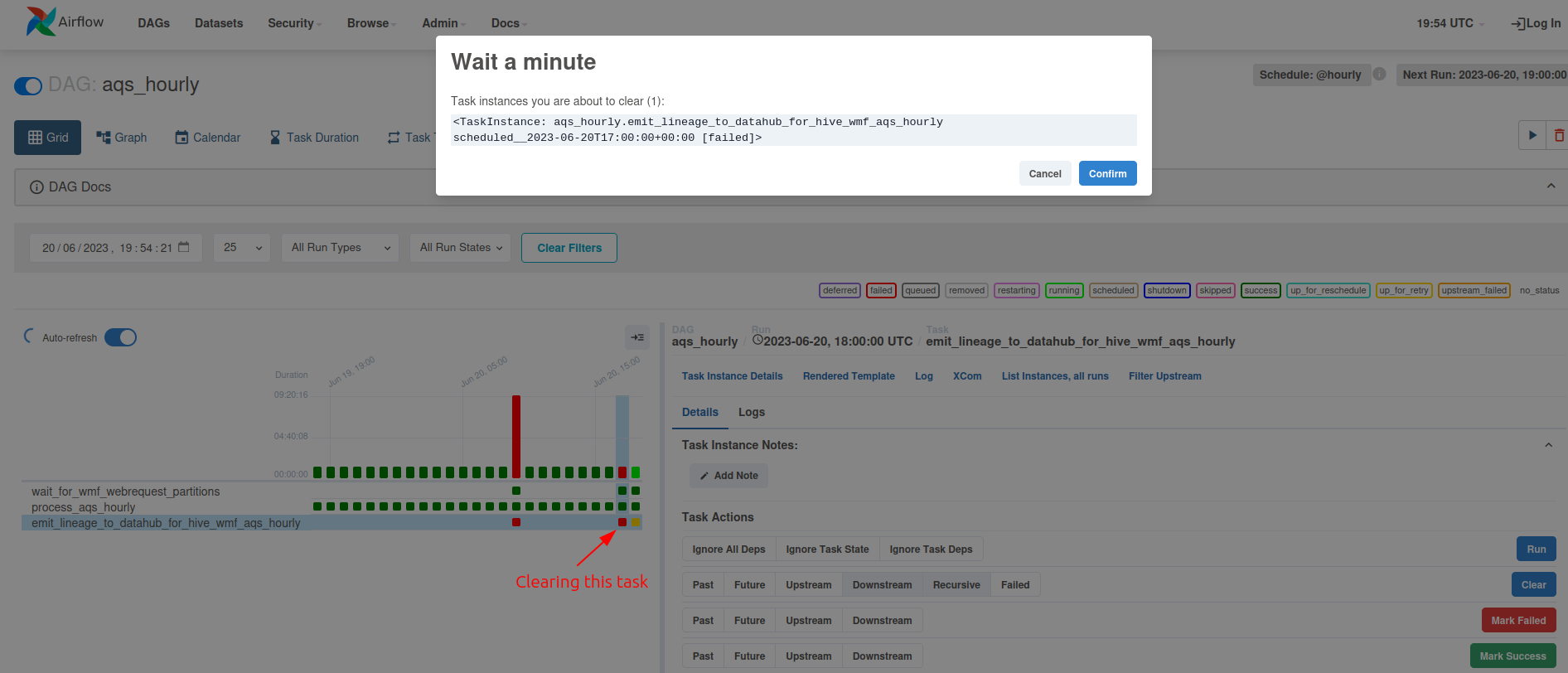
- 19:55 btullis: clearing the first failed emit_lineage_to_datahub_for_hive_wmf_aqs_hourly task https://usercontent.irccloud-cdn.com/file/vW6YdEof/image.png
- 19:51 btullis: merging https://gerrit.wikimedia.org/r/c/operations/puppet/+/931683 to fix the aqs_hourly datahub lineage failure
- 18:13 mforns: deployed airflow analytics to fix webrequest job
- 17:52 joal: deploy Refinery to unbreak webrequrest
{kind=link}
2023-06-19
[edit]- 14:04 elukey: move varnishafka instances in eqsin to PKI - T337825
- 11:28 stevemunene: decommission host analytics1060.eqiad.wmnet -t T338409
- 10:47 stevemunene: decommission host analytics1059.eqiad.wmnet -t T338408
- 09:13 stevemunene: Decommissioning analytics1058.eqiad.wmnet -t T338227
2023-06-16
[edit]- 12:18 btullis: restarting the remaining monitor_refine_event_sanitized_analytics_immediate.service monitor_refine_event_sanitized_main_delayed.service monitor_refine_event_sanitized_main_immediate.service services on an-launcher1002
- 12:11 btullis: restarting refine_event_sanitized_main_delayed.service on an-launcher1002
- 12:03 btullis: restarting refine_event_sanitized_analytics_delayed.service on an-launcher1002
- 11:14 btullis: rebooting an-test-worker1002 for T335358 and stuck gobblin
- 10:13 joal: rerun druid_load_edit_hourly to reload full snapshot
2023-06-15
[edit]- 19:27 btullis: restarting aqs service on A:aqs in batches of 2, 10 seconds apart
- 17:02 joal: Deploying airflow (again) to fix memory issues
- 15:58 joal: Rerun druid indexation for mediawiki_history_reduced
- 15:56 joal: Deploy airflow to fix druid loading jobs using snapshot
- 15:53 milimetric: refinery-source 0.2.17 deployed, refinery updated and synced to hdfs
- 12:47 stevemunene: roll running sre.hadoop.roll-restart-masters to completely remove any reference of analytics1058-1060 for T317861
- 12:34 joal: Deploy analytics-airlfow to patch mediawiki_history_reduced druid loading
- 09:05 elukey: move varnishkafka instances in ulsfo to PKI
2023-06-14
[edit]- 20:18 milimetric: reran mediawiki_history_reduced druid load task after deploying Joseph's fix
- 13:15 stevemunene: running the puppet on an-master100[1-2] Remove analytics58_60 from the HDFS topology T317861
2023-06-13
[edit]- 19:27 btullis: restarting the hive-server2 and hive-metastore services on an-coord1001
- 19:03 btullis: freeing up space in /srv on an-launcher1002 with `btullis@an-launcher1002:/srv/airflow-analytics/logs/scheduler$ find -maxdepth 1 -type d -mtime +15 -print0 | xargs -0 sudo rm -rf` for T339002
- 16:41 ottomata: deploying refinery for weekly train
- 15:45 SandraEbele: Deployed refinery-source using jenkins
- 15:19 ottomata: drop event.mediawiki_page_outlink_topic_prediction_change table and data - T337395
- 15:13 SandraEbele: deploying refinery source
- 15:05 ottomata: dropping hive table event.mediawiki_page_change_v1 to pick up backwards incompatible schema change - T337395
- 15:03 btullis: failing over the analytics-hive cname to an-coord1002
- 13:45 elukey: fixed broken graphs in the varnishkafka's dashboard
- 13:37 btullis: restarting hive-server2 and hive-metastore on an-coord1002 prior to failover.
- 13:00 btullis: rolled out conda-analytics 0.0.18 to analytics-airflow and hadoop-coordinator
- 12:25 btullis: beginning rollout of conda-analytics 0.0.18 to hadoop-workers
- 07:10 elukey: move varnishkafka instances on cp4037 to PKI TLS certs
2023-06-12
[edit]- 12:39 btullis: ran apt clean on an-testui1001 to get some free disk space.
- 11:30 btullis: resuming deployment of eventgate-main
- 09:58 btullis: deploying eventgate-main
- 08:52 btullis: restart monitor_refine_netflow service on an-launcher1002 after successful job re-run.
- 08:36 btullis: re-running the refine_netflow task
2023-06-09
[edit]- 20:40 btullis: restarting the aqs service more quickly with: `sudo cumin -b 2 -s 10 A:aqs 'systemctl restart aqs'`
- 20:23 btullis: btullis@cumin1001:~$ sudo cookbook sre.aqs.roll-restart-reboot --alias aqs restart_daemons --reason aqs_rollback_btullis
- 20:22 btullis: merged and deployed https://gerrit.wikimedia.org/r/c/operations/puppet/+/928927 to revert aqs mediawiki snapshot change
2023-06-08
[edit]- 17:12 btullis: running the sre.hadoop.roll-restart-masters cookbook for the analytics cluster, to pick up the new journalnode for T338336
- 17:01 btullis: running puppet on an-worker1142 to start the new journalnode
- 06:42 stevemunene: stop hadoop-hdfs-journalnode on analytics1069 in order to swap the journal node with an-worker1142 T338336
- 06:10 elukey: kill remaining processes for `andyrussg` on stat100x nodes to unblock puppet
2023-06-07
[edit]- 15:38 btullis: installing presto 0.281 to the test cluster
- 15:23 elukey: all varnishkafka instances on caching nodes are getting restarted due to https://gerrit.wikimedia.org/r/c/operations/puppet/+/928087 - T337825
- 14:13 btullis: running `sudo cumin A:wikireplicas-web 'maintain-views --all-databases --table abuse_filter_history --replace-all` on A:wikireplicas-web
- 14:04 btullis: running `maintain-views --all-databases --table abuse_filter_history --replace-all` on A:wikireplicas-analytics
- 11:52 btullis: running `sudo maintain-views --all-databases --table abuse_filter_history --replace-all` on clouddbd1021 for T315426
- 08:02 elukey: set "loadByPeriod(P15D+future), dropForever" for webrequest_sampled_live in druid-analytics - T337460
2023-06-06
[edit]- 15:52 elukey: restart yarn resourcemanager on an-master1002 to restore the Yarn UI (that works only when the active yarn RM is on 1001)
- 15:07 mforns: deployed airflow analytics to try and fix the edit_hourly DAG again
- 13:09 ottomata: EventStreamConfig - temporarily Disable canary events and hadoop ingestion for development.network.probe stream - T332024
- 11:29 stevemunene: service hadoop-yarn-resourcemanager restart for T317861
- 11:13 btullis: restart airflow-scheduler service on an-test-client1001 for analytics_test instance
- 11:12 btullis: restart airflow-scheduler service on an-airflow1006 for product_analytics instance
- 11:12 btullis: restart airflow-scheduler service on an-airflow1005 for search instance
- 11:08 btullis: restart airflow-scheduler service on an-airflow1002 for research instance
- 11:07 btullis: (correction) that should have read an-airflow1004 for platform_eng instance
- 11:06 btullis: restart airflow-scheduler service on an-launcher1004 for postgresql restart
- 11:05 btullis: restart airflow-scheduler service on an-launcher1002 for postgresql restart
- 05:41 stevemunene: hadoop-yarn-resourcemanager restart for T317861
2023-06-05
[edit]- 18:20 btullis: restarted haproxy service on dbproxy1018 for T338172
- 16:21 btullis: depooling service=wikireplicas-a,name=dbproxy1018.eqiad.wmnet
- 16:20 btullis: pooling service=wikireplicas-a,name=dbproxy1019.eqiad.wmnet to allow us to depool the analytics wikireplica servers
- 15:19 mforns: deployed airflow analytics to fix edit_hourly DAG
- 11:43 btullis: sudo -u hdfs /usr/bin/hdfs haadmin -failover an-master1002-eqiad-wmnet an-master1001-eqiad-wmnet
- 09:52 btullis: powered up an-worker1125
2023-06-01
[edit]- 19:09 mforns: deploy airflow analytics to bump up cassandra load monthly for top articles
- 17:50 mforns: deployed airflow analytics to unbreak monthly cassandra loading DAGs
- 14:13 mforns: deployed airflow analytics to fix anomaly detection ooms
2023-05-31
[edit]- 20:41 mforns: finished refinery deployment
- 20:20 mforns: starting refinery deployment
- 07:29 elukey: set "loadByPeriod(P8D+future), dropForever" for webrequest_sampled_live in druid-analytics - T337460
2023-05-30
[edit]- 15:52 xcollazo: created HDFS folder `/wmf/data/wmf_traffic` (T335305 and T337562)
2023-05-26
[edit]- 06:42 elukey: `apt-get clean` on stat1008 to clean up some space in the root partition
- 06:36 elukey: `truncate /var/log/kerberos/krb5kdc.log -s 10g` on krb1001 to avoid the root partition to fill up
2023-05-25
[edit]- 13:42 joal: rerun webrequest-refine job for 2023-05-20T00 - we're missing data
- 12:31 elukey: set "loadByPeriod(P3D+future), dropForever" for webrequest_sampled_live in druid-analytics - T337460
- 08:37 joal: rerun druid_load_webrequest_sampled_128_daily 2023-05-20 to reload missing hour (T337088)
- 08:37 joal: rerun druid_load_webrequest_sampled_128_daily
2023-05-24
[edit]- 16:19 aqu: Deployed refinery using scap, then deployed onto hdfs
- 16:05 elukey: move kafka mirror on kafka main brokers to PKI - T337248
- 15:56 elukey: move kafka mirror on kafka jumbo brokers to PKI - T337248
- 15:48 elukey: run `kafka acls --add --allow-principal User:CN=kafka_mirror_maker --producer --topic '*'` on kafka test - T337248
- 15:18 aqu: analytics-refinery, about to deploy
- 12:21 joal: rerun failed druid_load_pageviews_hourly_aggregated_daily 2023-05-17
- 12:21 joal: rerun failed druid_load_pageviews_hourly_aggregated_daily
2023-05-23
[edit]- 10:01 stevemunene: reboot an-test-master1001.eqiad.wmnet December 2022 Buster reboots T325132
- 09:33 stevemunene: reboot an-test-coord1001.eqiad.wmnetDecember 2022 Buster reboots T325132
- 08:22 btullis: installing conda-analytics-0.0.17.dev_amd64.deb to an-test-worker1001 for T332765
2023-05-22
[edit]- 22:12 btullis: installing conda-analytics-0.0.17.dev_amd64.deb to an-test-client1001 for T332765
2023-05-19
[edit]- 13:23 btullis: restart monitor_refine_eventlogging_analytics.service on an-launcher1002
2023-05-18
[edit]- 16:54 btullis: systemctl reset-failed services on stat1008
- 16:53 btullis: installing conda-analytics 0.0.15 to an-test-worker1001 for T332765
- 15:49 mforns: deployed airflow analytics_test
- 14:22 btullis: systemctl reset-failed user manager services on stat1004
- 12:46 elukey: clean up old jupyterhub.service references (crash looping) on stat* nodes that had it
- 10:31 btullis: cold booting an-worker1110 to troubleshoot drive failure T336929
2023-05-17
[edit]- 17:58 ottomata: Deployed refinery-source using jenkins
- 13:22 btullis: roll-rebooting dse-k8s-workers via cookbook
- 13:17 btullis: roll-rebooting an-worker1[096-101] for T335835
2023-05-16
[edit]- 17:59 joal: rerun druid_load_pageviews_daily_aggregated_monthly
- 17:34 joal: Stop, delete then restart airflow druid_load_banner_activity jobs
- 17:34 joal: deploy fix for airflow druid_load_banner_activity jobs
- 15:58 joal: Kill oozie banner_activity-druid-monthly-coord job
- 15:57 joal: Start airflow druid_load_banner_activity_minutely_aggregated_monthly
- 15:55 joal: Kill oozie banner_activity_daily job
- 15:55 joal: Start airflow duid_load_banner_activity_minutely
- 15:51 joal: Kill oozie mediawiki_history_reduced job
- 15:50 joal: Start airflow mediawiki_history_reduced job with start-date to 2023-05-01
- 15:45 joal: Clear failed wikidata_item_page_link sensor task after deploy - due to datacenter switcover
- 15:41 joal: Deploying analytics airflow dags
- 14:00 joal: Deploy refinery onto HDFS
- 13:40 btullis: pooled schema2004 for T335042
- 11:45 joal: Deploy refinery using scap
- 11:04 btullis: depooled schema2004 for T335042
2023-05-15
[edit]- 07:16 joal: Rerun failed refine_eventlogging_legacy job for universallanguageselector
- 07:02 joal: Rerun failed refine_event job for content_translation_event
2023-05-12
[edit]- 16:05 mforns: dropped mobile_apps_* hive tables because of https://phabricator.wikimedia.org/T329310
2023-05-11
[edit]- 14:55 xcollazo: replaced /user/spark/share/lib/spark-3.1.2-assembly.jar in HDFS with new version that includes Iceberg.
2023-05-10
[edit]- 20:37 milimetric: deployed refinery (except to an-airflow1001)
- 16:50 stevemunene: deploy conda-analytics v0.0.13 T335721
- 16:36 btullis: installing airflow 2.6.0 on an-test-client1001 for T336286
- 15:51 mforns: stopped Airflow DAG mobile_app_session_metrics_weekly because of https://phabricator.wikimedia.org/T329310
- 15:50 mforns: killed oozie job mobile_apps-uniques-monthly-coord because of https://phabricator.wikimedia.org/T329310
2023-05-09
[edit]- 13:02 btullis: rebooting an-worker1088 after firmware upgrade for T336077
- 12:59 btullis: upgrading SAS RAID controller firmware on an-worker1088 for T336077
- 12:27 btullis: rebooting eventlog1003 for T325132
2023-05-08
[edit]- 21:22 mforns: deployed airflow analytics for a quick fix
2023-05-05
[edit]- 15:44 mforns: re-ran projectview_hourly DAG for 2023-05-05T13
- 15:06 mforns: deployed airflow analytics
- 14:26 btullis: roll-rebooting presto workers for T335835
2023-05-04
[edit]- 20:12 btullis: executed `sudo apt clean` on stat1005 to free up some space.
- 20:09 btullis: restarting hive-server2 and hive-metastore on an-coord1002
- 14:07 btullis: failing back hive service to an-coord1001
2023-05-03
[edit]- 21:43 milimetric: deployed refinery-source and refinery to prepare for launching new airflow druid jobs
2023-05-02
[edit]- 18:20 milimetric: deployed refinery as part of weekly train
- 16:24 btullis: roll-restarting AQS
- 13:49 btullis: deploying updated mediawiki history snapshot to aqs
- 09:33 btullis: depooled schema2003 for T334049
2023-04-26
[edit]- 11:12 btullis: restart refine_netflow service on an-launcher1002.
- 10:55 btullis: deploying refinery to hdfs
- 09:12 btullis: deploying refinery
2023-04-25
[edit]- 13:47 btullis: rebooting an-test-worker1002 T335358
- 13:07 btullis: restarted the gobblin-eventlogging_legacy_test on an-test-coord1001
- 13:06 btullis: killed the gobblin-eventlogging_legacy_test on an-test-coord1001
2023-04-24
[edit]- 09:40 btullis: upgrading RAID controller firmware an an-worker1110 T334832
2023-04-20
[edit]- 16:25 SandraEbele: Deployed refinery using scap, then deployed onto hdfs as part of weekly deployment train.
- 15:44 SandraEbele: deploying weekly deployment train for analytics refinery.
2023-04-18
[edit]- 15:49 btullis: restarting refinery-drop-raw-netflow-event.service refinery-drop-webrequest-raw-partitions.service refinery-drop-webrequest-refined-partitions.service on an-launchger1002
- 15:48 btullis: restart refinery-drop-raw-event.service on an-launcher1002
- 15:45 btullis: restart refinery-drop-pageview-actor-hourly-partitions.service on an-launcher1002
- 15:44 btullis: restart refinery-drop-eventlogging-legacy-raw-partitions.service on an-launcher1002
- 15:42 btullis: restart drop-webrequest-actor-metrics-rollup-hourly.service on an-launcher1002
- 15:40 btullis: restart drop-webrequest-actor-metrics-hourly.service on an-launcher1002
- 14:51 btullis: restart drop-webrequest-actor-label-hourly.service on an-launcher1002
- 13:56 btullis: re-enabling gobblin timers
- 13:52 btullis: pooled schema1004
- 13:51 btullis: pooled aqs10[14,15,19]
- 13:49 btullis: re-enabling YARN queues
- 13:43 btullis: leaving HDFS safe mode on an-master1001
- 11:55 btullis: entering safe mode for prod hadoop HDFS
- 11:48 btullis: depooled aqs10[14,15,19]
- 11:45 btullis: depooled schema1004 T333377
- 11:41 btullis: refreshed yarn queues with `sudo cumin '(A:hadoop-master or A:hadoop-standby)' 'kerberos-run-command yarn /usr/bin/yarn rmadmin -refreshQueues'`
- 11:36 btullis: stopping YARN queues T333377
- 11:34 btullis: disable gobblin timers T333377
- 08:39 btullis: rebooting an-worker1110 to attempt upgrading RAID controller firmware
2023-04-17
[edit]- 20:48 joal: Restart AQS to pick up druid new datasource using scap
- 18:34 xcollazo: Removed old Airflow cached artifacts. Details at T334886.
- 17:26 SandraEbele: restarted turnilo with ‘sudo systemctl restart turnilo’
- 17:13 SandraEbele: restarted Oozie page view-druid-daily job 0174450-220913162928808-oozie-oozi-C
- 17:00 xcollazo: scap deploy 'analytics: deploy Airflow ArchiveOperator should have a number of retries of 0. T332216'
- 16:56 SandraEbele: restarted oozie page view-druid-hourly job 0174449-220913162928808-oozie-oozi-C
- 11:12 btullis: running sre.hadoop.init-hadoop-workers an-worker1132.eqiad.wmnet
- 10:32 btullis: reimaging an-worker1132
2023-04-13
[edit]- 21:37 SandraEbele: Successfully Deployed analytics refinery using scap, then deployed onto hdfs.
- 15:42 SandraEbele: paused Oozie pageview-druid-hourly job.
- 15:27 SandraEbele: deploying analytics refinery-update pageview druid table
- 08:19 steve_munene: Decommission an-worker1132 from the Hadoop cluster for T333091 reimage
2023-04-12
[edit]- 15:16 mforns: cleared airflow task aggregate_projectview_geographically from dag projectview_geo for 2023-04-12T08->09
- 14:50 mforns: cleared airflow task aggregrate_pageview_to_projectview from projectview_hourly dag for 2023-04-12Y08->09
- 14:39 mforns: cleared airflow task aggregate_pageview_actor_to_pageview_hourly from dag pageview_hourly for 2023-04-12T08->09
- 14:30 mforns: re-ran airflow task compute_pageview_actor_hourly for dag pageview_actor_hourly for 2023-04-12T08->09
- 09:24 aqu: About to migrate refine webrequest form Oozie to Airflow
- 08:31 aqu: About to deploy analytics/refinery in production
2023-04-11
[edit]- 20:22 mforns: deployed airflow analytics to remove network flows sanitization dag
- 19:17 SandraEbele: Unpaused pageview_hourly airflow dag.
- 19:17 SandraEbele: deployed airflow fix for pageview_hourly dag memory error
- 16:28 mforns: deployed airflow analytics to fix network flows internal dags in deployment
- 15:27 SandraEbele: Deployed refinery using scap, then deployed onto hdfs.
- 13:46 elukey: powercycle analytics1069, down for some days now, host stuck from the mgmt/serial console
- 08:14 aqu: About to deploy analytics/refinery (To migrate webrequest load from Oozie to Airflow)
2023-04-10
[edit]- 19:20 mforns: deployed airflow analytics to fix mediawiki wikitext history
2023-04-07
[edit]- 10:34 aqu: About to deploy analytics/refinery in test cluster
2023-04-05
[edit]- 20:17 mforns: deployed airflow to fix aqs pageview ranks
- 20:08 mforns: finished second refinery deployment to fix aqs rankings
- 19:54 mforns: starting second refinery deployment to fix aqs rankings
- 19:35 mforns: finished refinery deployment to fix aqs rankings\
- 19:18 mforns: starting refinery deployment to fix aqs rankings
- 16:24 elukey: kafka test cluster migrated to bullseye
- 14:00 elukey: powercycle an-worker1132
2023-04-04
[edit]- 13:39 steve_munene: leave hdfs safemode T331882
- 12:57 steve_munene: putting hdfs into safe mode as part of T331882
- 11:42 elukey: stop puppet on an-launcher1002 and manually stop .timer units
- 07:34 aqu: Rerun refine_event with "sudo -u analytics kerberos-run-command analytics /usr/local/bin/refine_event --ignore_failure_flag=true --table_include_regex='mediawiki_visual_editor_feature_use|mediawiki_edit_attempt|mediawiki_web_ui_interactions' --since='2023-04-02T18:00:00.000Z' --until='2023-04-03T19:00:00.000Z'"
2023-04-03
[edit]- 08:01 elukey: fix old envoyproxy monitor for an-test-ui1001
2023-03-31
[edit]- 12:23 btullis: deploying datahub to staging T333580
- 08:44 btullis: Shutting down an-worker1091 for RAID battery replacement T332883
2023-03-30
[edit]- 18:32 SandraEbele: started Airflow mediwiki wikitext dags after killing oozie jobs as part of Migration task.
- 18:31 SandraEbele: Killed Oozie mediawiki-wikitext-history-coord and mediawiki-wikitext-current-coord
- 18:28 SandraEbele: deployed hotfix for airflow mediawiki_wikitext_current and mediawiki_wikitext_history dags.
- 17:30 SandraEbele: deployed airflow analytics - mediawiki_wikitext dags
- 17:20 SandraEbele: killed Oozie mediawiki-history-check_denormalize job and started Airflow mediawiki_history_check_denormalize dag.
- 12:32 joal: Deploy airflow hotfix for referer_daily
- 12:11 joal: Kill virtualpageview oozie job - migrated to airflow
- 11:56 joal: Kill oozie referer_daily job - migrated to airflow
- 09:56 btullis: re-running refine_event
- 09:48 joal: Deploy airflow analytics
- 09:38 joal: Deploying refinery onto HDFS
- 09:27 joal: Deploying refinery using scap
2023-03-28
[edit]- 15:58 btullis: deploying refinery to HDFS
- 14:35 btullis: re-enabling gobblin timers: https://gerrit.wikimedia.org/r/c/operations/puppet/+/903668 T330165
- 14:31 btullis: re-enabling YARN queues: https://gerrit.wikimedia.org/r/c/operations/puppet/+/903565 T330165
- 14:25 btullis: proceeding to take HDFS out of safe mode.
- 14:25 btullis: restarting hive-server2 and hive-metastore services on an-coord1001
- 13:54 btullis: entering safe mode for analytics-hadoop cluster: T330165
- 13:37 btullis: refreshed YARN queues with: `sudo kerberos-run-command yarn /usr/bin/yarn rmadmin -refreshQueues` on both an-master100[1-2] - T330165
- 13:31 btullis: setting all four YARN queues to STOPPED https://gerrit.wikimedia.org/r/c/operations/puppet/+/903627 T330165
- 12:50 btullis: merging the change to disable ingestion to HDFS https://gerrit.wikimedia.org/r/c/operations/puppet/+/903610
- 10:46 btullis: failing over hive services to an-coord1002 prior to switch upgrade.
2023-03-27
[edit]- 17:19 milimetric: added 2023-03-14T11 and 2023-03-14T12 partitions for codfw on event.mediawiki_page_move with alter table mediawiki_page_move add partition (datacenter='codfw',year=2023,month=3,day=14,hour=[11,12]);
2023-03-24
[edit]- 14:43 topranks: merged alertmanager rules for eventlogging checks being migrated from Icinga T309007
2023-03-23
[edit]- 13:48 joal: Restart virtualpageview-hourly-coord with pageview_allowlist fix - starting 2023-03-21T08:00
- 13:47 joal: Kill oozie virtualpageview-hourly-coord job
- 13:29 joal: Hotfix deploy refinery
- 11:37 btullis: we changed the retention policy on an-test-druid to `{"period":"P1M","includeFuture":true,"tieredReplicants":{"_default_tier":1},"type":"loadByPeriod"},{"type":"dropForever"}`
- 11:36 btullis: reimaging an-test-druid1001 in place to upgrade to bullseye
- 08:28 joal: Rerun failed virtualpageview-druid-daily-wf-2023-3-22
2023-03-21
[edit]- 17:48 joal: rerun failed airflow tasks
- 17:39 joal: Deploy airflow, hopefully fixing HDFSArchiver jobs
- 13:21 nfraison_: deploy last changes on k8s dse cluster (dse-k8s-eqiad: flink-operator should watch rdf-streaming-updater, enable spark operator mutation webhook, Allow communication from spark pods to HDFS/Hive)
- 11:01 joal: Deploy analytics airflow code
- 10:49 nfraison_: deployment last changes on k8s dse cluster failed due to certificate secret creation failure due to timeout contacting pki.discovery.wmnet
- 10:41 joal: Unpause pageview_actor airflow dag
- 10:41 joal: Alter wmf.pageview_actor table adding referer_data field
- 10:31 nfraison_: deploy last changes on k8s dse cluster (dse-k8s-eqiad: flink-operator should watch rdf-streaming-updater, enable spark operator mutation webhook, Allow communication from spark pods to HDFS/Hive)
- 10:26 joal: Deploy refinery onto HDFS
- 10:25 joal: Pause pageview_actor airflow job during HDFS refinery deploy and alter table update
- 10:13 joal: Deploy refinery with scap sorry
- 10:13 joal: Deploy refinery with sqoop
2023-03-17
[edit]- 07:45 nfraison_: reset failed session-c624.scope as last issue was on March 14 on an-worker1132
- 07:42 joal: Rerun failed refine_event job
2023-03-16
[edit]- 17:00 btullis: enabling puppet on an-airflow1004 to restart airflow services.
- 16:51 btullis: upgrading airflow package on an-airflow1004
- 16:29 btullis: stopping puppet and airflow services on an-airflow1004 for the upgrade.
2023-03-15
[edit]- 18:37 joal: Manually creating partitions for event.mediawiki_client_session_tick (datacenter=eqiad/year=2023/month=3/day=7/hour=[10,11,12,13,14])
- 13:10 btullis: rerunning eventlogging_legacy failed job
- 11:18 btullis: stopping the matomo database replica on db1108
2023-03-14
[edit]- 14:57 btullis: deploying ceph mon and mgr daemons to cephosd100[1-5] T328123
- 11:48 btullis: reran refine_event_sanitized_analytics_immediate for netflow year=2023/month=3/day=8/hour=6
- 10:23 btullis: deploying airflow package version 2.5.1-py3.10-20230228 to stats hosts
2023-03-13
[edit]- 17:14 nfraison_: restart jobhistory in prod cluster to take in account https://gerrit.wikimedia.org/r/c/operations/puppet/+/896305
- 17:08 nfraison_: restart jobhistory in test cluster to take in account https://gerrit.wikimedia.org/r/c/operations/puppet/+/896305
- 13:53 milimetric: killing pageview-monthly_dump-coord, pageview-daily_dump-coord, and pageview-hourly-coord oozie jobs to migrate to airflow
- 13:24 btullis: restarting an-worker1140
2023-03-10
[edit]- 20:04 milimetric: deployed refinery with new pageview jobs, patched in a manual copy of static_data/pageview/whitelist/whitelist.tsv because that file was renamed in the most recent version and would have broken jobs otherwise
2023-03-09
[edit]- 19:47 btullis: shutting down an-worker1078 for RAID BBU replacement T331544
- 18:51 mforns: deployed airflow analytics (2.5) with the T326194_airflow_deb_creation_with_gitlab_ci branch
- 17:55 joal: Force kill druid indexing task to unlock druid_load_navigationtiming_daily__load_to_druid__20230228
- 17:46 btullis: deploying spark-operator once more
- 16:49 btullis: deploying updated spark-operator to dse-k8s cluster.
- 14:04 btullis: airflow services were started automatically. airflow db check was successful.
- 14:00 btullis: running puppet on an-launcer1002 to pull the new package after https://gerrit.wikimedia.org/r/c/operations/puppet/+/896098 is merged.
- 13:06 steve_munene: upgrading analytics airflow to 2.5.1 on an-launcher1002
2023-03-08
[edit]- 11:54 ottomata: Deployed refinery using scap, then deployed onto hdfs
- 10:36 nfraison: restart namenode in an-master1002 to take in account new quota init threads setting
- 10:25 nfraison: failover namenode in prod from an-master1002-eqiad-wmnet to an-master1001-eqiad-wmnet
- 09:59 nfraison: restart namenode in an-master1001 (standby in prod) to take in account new quota init threads setting
- 09:53 nfraison: restart namenode in an-test-master1002 to take in account new quota init threads setting
- 09:52 nfraison: failover namenode in test from an-test-master1002-eqiad-wmnet to an-test-master1001-eqiad-wmnet
- 09:47 nfraison: restart namenode in an-test-master1001 to take in account new quota init threads setting
- 09:36 nfraison: restart test hiveserver2: T303168
- 09:13 nfraison: restart prod resourcemanager to take in account new dedicated exclude file
- 08:58 nfraison: restart test resourcemanager to take in account new dedicated exclude file
- 07:56 nfraison: restart prod jobhistory to take in account: https://gerrit.wikimedia.org/r/c/operations/puppet/+/894481
- 07:47 nfraison: restart test jobhistory to take in account: https://gerrit.wikimedia.org/r/c/operations/puppet/+/894481
2023-03-07
[edit]- 22:03 mforns: deployed airflow analytics again to try and fix druid_load_edit_hourly
- 16:55 xcollazo: deployed image-suggestions hotfix to platform_eng Airflow instance. See https://gitlab.wikimedia.org/repos/data-engineering/airflow-dags/-/merge_requests/262.
- 15:23 btullis: re-enabling ingestion via gobblin.
- 14:59 nfraison: force startup of nodemanager on analytics_cluster
- 14:58 btullis: pooled druid1004
- 14:57 btullis: pooling aqs1010 and aqs1016
- 14:56 btullis: pooling datahubsearch1001
- 14:53 btullis: leaving safe mode on hdfs
- 13:59 btullis: disabled puppet temporarily on an-master100[1-2] to avoid an automatic restart of yarn
- 13:57 btullis: stopped `hadoop-yarn-resourcemanager.service` on both an-master100[1-2]
- 13:54 btullis: entering safe mode with `sudo -u hdfs kerberos-run-command hdfs hadoop dfsadmin -safemode enter` on an-master1002
- 12:57 btullis: depooled druid1004 for T329073
- 12:56 btullis: depooled datahubsearch1001 for T329073
- 12:51 btullis: disabled gobblin timers on an-launcher1002
- 12:46 btullis: depooling aqs1016for T329073
- 12:45 btullis: depooling aqs1010 for T329073
- 08:00 nfraison: Reimage an-conf1003 to upgrade to bullseye T329362
2023-03-06
[edit]- 23:12 mforns: deployed airflow analytics to unbreak druid-load-edit-hourly
- 15:26 mforns: deployed airflow analytics to unbreak druid-load-edit-hourly
- 13:53 btullis: failing over the production hadoop cluster namenode service to an-master1002
- 13:17 btullis: failing over analytics test cluster namenode service to an-test-master1002 T329073
- 12:26 nfraison: Reimage an-conf1002 to upgrade to bullseye T329362
- 10:15 ottomata: deploy mediawiki_history_reduced_2023_02 snapshot to AQS
- 09:23 nfraison: Reimage an-conf1001 to upgrade to bullseye T329362
2023-03-03
[edit]- 16:48 xcollazo: Deleted snapshot=2023-02-20 for tables image_suggestions_search_index_full, image_suggestions_search_index_delta, image_suggestions_lead_image_data and image_suggestions_wikidata_data from the analytics_platform_eng schema. This data will be regenerated. See https://phabricator.wikimedia.org/T330688.
- 15:53 mforns: deployed airflow analytics to unbreak edit_hourly_dag
- 15:44 xcollazo: Deploying latest image_suggestions DAG on platform_eng Airflow instance
- 07:29 elukey: truncate /var/log/auth.log.1 on krb1001 to free space (root partition almost filled up)
2023-03-02
[edit]- 13:27 nfraison: airflow on an-test-client1001 is migrated to version 2.5.1
- 12:32 joal: Rerun mediawiki-history-denormalize-wf-2023-02
- 10:00 btullis: commencing second attempt to upgrade airflow on an-test-client1001 to version 2.5.1
2023-03-01
[edit]- 22:45 mforns: re-deployed airflow analytics with some forgotten changes
- 22:42 mforns: deployed Airflow analytics
- 22:30 mforns: finished refinery deployment, although didn't manage to run refinery-deploy-to-hdfs without warnings...
- 21:48 mforns: kill edit-hourly-coord in Hue to migrate it to Airflow
- 21:26 mforns: starting refinery deploy
- 19:38 SandraEbele: rerunning webrequest load text for 2023-03-01-08 hour.
- 18:54 joal: Create empty partitions in event.mediawiki_page_move table for codfw datacenter from beginning of week (2023-02-27T00 -> 2023-02-28T13)
- 10:25 nfraison: rebooting an-worker1132 being slower than other node (potential issue with raid card/disks)
- 07:59 nfraison: restarted hiveserver2 in analytics-test to take in account -XX:MaxMetaspaceSize=512m JVM parameter
2023-02-28
[edit]- 21:33 xcollazo: Deploying section_image_recommendations DAG to platform_eng Airflow instance
- 11:38 btullis: cancelled merge of https://gerrit.wikimedia.org/r/c/operations/puppet/+/878128
- 11:32 btullis: merging https://gerrit.wikimedia.org/r/c/operations/puppet/+/878128
- 09:42 nfraison: restart presto prod coordinator to take in account heap size change
- 09:38 nfraison: Failover hive servers to active server: an-coord1001
- 09:32 nfraison: restarted hive-metastore and hiveserver2 on an-coord1001 (non-active hive server)
- 08:22 nfraison: Failover hive servers to standby server: https://gerrit.wikimedia.org/r/c/operations/dns/+/892460
2023-02-27
[edit]- 14:52 nfraison: restarted hive-metastore and hiveserver2 on an-coord1002 (standby hive server)
2023-02-22
[edit]- 19:39 mforns: restarted the following an-launcher1002 timers, which seemed stuck (next run = n/a): gobblin-webrequest.timer, reportupdater-browser.timer, reportupdater-reference-previews.timer, refine_event.timer, refine_eventlogging_legacy.timer
- 11:07 nfraison: roll restart presto clusters to take in account fix on node.environment typo
2023-02-21
[edit]- 19:01 mforns: re airflow silent failure: the job was pageview_actor_hourly
- 19:00 mforns: we had another silent failure in airflow, a sensor that failed without sending an email. the logs are missing.
- 09:33 nfraison: adding last batch of 5 nodes to the presto prod cluster
2023-02-20
[edit]- 13:11 nfraison: Reimage an-presto1001 to upgrade to bullseye T329361
- 12:45 nfraison: adding 5 nodes to the presto prod cluster
- 12:32 nfraison: roll-restart presto workers on an-presto100[1-5] to take in account new configs T329525
- 12:29 nfraison: restart presto coordinator on an-coord1001 to take in account new configs T329525
2023-02-18
[edit]- 08:29 elukey: kill leftover processes of user `mepps` (offboarded) from stat100[4,5] to unblock puppet
2023-02-16
[edit]- 21:10 SandraEbele: restarted oozie webrequest load bundle.
- 21:09 SandraEbele: Added new field referer_data to wmf.webrequest table using the alter table statement
- 21:07 SandraEbele: successfully deployed analytics refinery
- 18:46 SandraEbele: started deploying analytics refinery
- 18:37 SandraEbele: killed webrequest bundle ooze jobs to deploy refinery changes.
- 16:55 SandraEbele: Deployed refinery-source change to remove Github.io from Mediasites definition of referers.
2023-02-13
[edit]- 21:40 xcollazo: deploying section_topics v0.5.0 on platform_eng Airflow instance
- 21:39 ottomata: enabled rc1.mediawiki.page_change stream on group0 and group1 wikis
- 14:15 btullis: roll-restarting all eventgate pods
- 14:06 nfraison: Reimage an-test-presto1001 to upgrade to bullseye T329361
- 10:46 nfraison: restarting presto-worker on an-presto[1001-1015].eqiad.wmnet to pick up new gc logging settings T329054
- 10:15 btullis: Reimage an-test-worker1001 to upgrade to bullseye T329363
- 09:59 nfraison: restarting presto-coordinator on an-coord1001 to pick up new gc logging settings T329054
- 09:57 nfraison: re-enabled puppet agent on an-presto[1001-1015].eqiad.wmnet and an-coord1001.eqiad.wmnet
- 09:08 aqu: Rerun killed Oozie pageview-hourly-coord of 2023-02-11 with sudo -u analytics kerberos-run-command analytics oozie job --oozie $OOZIE_URL -rerun 0019103-210107075406929-oozie-oozi-C -date 2023-02-11T14:00Z::2023-02-11T16:00Z
- 09:04 nfraison: restarting presto-coordinator on an-test-coord1001 to pick up new gc logging settings T329054
- 08:59 nfraison: restarting presto-worker on an-test-presto1001 to pick up new gc logging settings T329054
- 08:52 nfraison: disabled puppet agent on an-presto[1001-1015].eqiad.wmnet and an-coord1001.eqiad.wmnet to apply https://gerrit.wikimedia.org/r/c/operations/puppet/+/888214 on test cluster first only
2023-02-10
[edit]- 23:22 mforns: unpaused all airflow dags and cleared all failed tasks after the incident
- 22:30 btullis: starting the hadoop-yarn-resourcemanager on an-master1001 and failing back to iy.
- 22:25 btullis: stopping hadoop-yarn-resourcemanager service in an-master1001 to fail over automatically to an-master1002
- 21:21 mforns: restarted airflow@analytics.service in an-launcher1002
2023-02-09
[edit]- 17:32 mforns: deployed airflow
- 12:01 btullis: Shutting down an-worker109[89] and dse-k8s-worker1002 for another GPU move - T318696
- 10:36 joal: Start airflow webrequest_actor jobs
- 10:26 joal: Deploy analytics-airflow
- 10:25 joal: Setup airflow start-date variables for new dags
- 10:10 joal: Merge airflow code for learning/actor -> webrequest_actor move
- 10:01 joal: Move data and update hive tables from learning/actor convention to webrequest_actor convention
- 09:59 joal: Kill oozie pageview-learning jobs
2023-02-08
[edit]- 19:26 milimetric: finished deploying refinery-source 0.2.11, refinery, and synced to hdfs
- 12:04 btullis: shut down an-worker109[67] and dse-k8s-worker1001 ready for GPU swap.
2023-02-03
[edit]- 15:23 milimetric: deployed airflow-dags/analytics to disable skein log collection from the SparkSubmitOperator.
- 10:11 steve_munene: roll-restart aqs to update mediawiki_history_snapshot to 2023-01
2023-02-02
[edit]- 12:26 btullis: deploying the updated build of superset to production T328047
- 09:56 btullis: correction: beginning a rolling reboot of all aqs servers for T325132
- 09:52 btullis: beginning a rolling reboot of all aqs servers for T326945
- 08:44 steve_munene: Deployed refinery using scap, then deployed onto hdfs
- 08:26 steve_munene: refinery-deploy-to-hdfs run4
2023-02-01
[edit]- 10:51 steve_munene: Deploying refinery for ops week
2023-01-30
[edit]- 16:41 btullis: started an-presto1006-1015 again, but disabled the presto service on them once again T323783 and T325809
2023-01-27
[edit]- 11:41 steve_munene: datahub helmfile apply on main for T327884
- 11:17 btullis: shut down an-worker1087 to await RAID BBU replacement
- 11:03 steve_munene: datahub: apply on main for T327884
2023-01-26
[edit]- 10:42 joal: deploying airflow analytics for GDI dags
- 10:36 joal: drop/recreate wmf_raw.mediawiki_private_cu_changes hive table to have new fields
- 10:01 joal: deploy refinery onto hdfs
- 09:48 joal: deploying refinery using scap (no refinery-source deploy)
- 09:43 joal: Rerun failed 'cassandra_daily_load.load_mediarequest_per_file_to_cassandra 2023-01-25T00:00:00+00:00' task
2023-01-25
[edit]- 16:54 steve_munene: Restarting presto-server.service on presto coordinator an-coord1001 for T323783
- 16:53 btullis: kicked off a rolling reboot of kafka-jumbo as part of T325132
- 15:14 btullis: rebooting an-conf1003 for new kernel
- 14:54 btullis: started a rolling-reboot of the hadoop workers via `sre.hadoop.reboot-workers` cookbook.
2023-01-23
[edit]- 13:06 btullis: restarted webrequest_sampled_supervisor realtime druid indexation job
- 10:04 btullis: proceeding to upgrade an-tool1010 to bullseye for superset 1.5.3 upgrade T323458
2023-01-19
[edit]- 10:25 btullis: enabled dashboard native filtering in superset https://gerrit.wikimedia.org/r/c/operations/puppet/+/881510 for T318299
2023-01-17
[edit]- 20:54 xcollazo: dropping old partitions from image_suggestions Hive tables as per https://phabricator.wikimedia.org/T325837
- 16:50 btullis: shutdown an-worker1086 for RAID BBU replacement
2023-01-16
[edit]- 08:46 elukey: powercycle an-worker1125 - soft lockup traces registered in the tty, host frozen
2023-01-10
[edit]- 17:33 btullis: chassis power reset on an-worker1032 (T326459)
- 15:58 SandraEbele: backfilling refine_event_sanitized_analytics_immediate on an-launcher1002 ‘sudo -u analytics kerberos-run-command analytics /usr/local/bin/refine_event_sanitized_analytics_immediate —ignore_failure_flag=true --since=2023-01-07T17:00:00 until=2023-01-08T10:00:00
- 15:55 SandraEbele: reran failed pageview-druid-hourly-coord oozie job for 2023-1-10-10.
- 11:36 btullis: roll-rebooting the analytics druid cluster to pick up new kernel
- 10:24 btullis: roll-rebooting the druid-public cluster to pick up new kernel
2023-01-09
[edit]- 17:09 aqu: Relaunching refine_event after partial backfilling `sudo systemctl start refine_event.service` (an-launcher1002)
- 14:48 SandraEbele: reran webrequest failed jobs ‘sudo -u analytics kerberos-run-command analytics oozie job --oozie $OOZIE_URL -Dstart_time=2023-01-08T07:00Z -Dstop_time=2023-01-08T14:59Z -Dwebrequest_source=text -Derror_incomplete_data_threshold=100 -Dwarning_incomplete_data_threshold=100 -Derror_data_loss_threshold=100 -Dwarning_data_loss_threshold=100 -submit -config /home/ebysans/webrequest_text_coordinator.properties’
- 10:21 aqu: backfilling with refine_event on an-launcher1002 `sudo -u analytics kerberos-run-command analytics /usr/local/bin/refine_event --ignore_failure_flag=true --since=2023-01-07T16:00:00 --until=2023-01-09T09:00:00 --verbose`
- 09:48 aqu: killing refine_event yarn application `sudo -u analytics yarn application -kill application_1663082229270_682638`
- 09:39 aqu: Manually kill the Spark process on an-launcher1002 `sudo -u analytics kill -9 28538`
2023-01-06
[edit]- 12:29 steve_munene: roll restarting aqs servers for to bump up mediawiki_history_snapshot to 2022-12
2023-01-04
[edit]- 17:14 xcollazo: Dropped all temporary differential privacy tables with the 'DROP DATABASE tumult_temp_*' pattern.
2023-01-03
[edit]- 11:08 btullis: restarted hive-server2 and hive-metastore services on an-coord1001 after failover to standby server
- 10:39 btullis: fail over hive services to an-coord1002 with change to the DNS CNAME for analytics-hive.eqiad.wmnet
- 10:20 btullis: restart hive-server2 and hive-metastore services on an-coord1002 prior to failover
2022-12-25
[edit]- 19:52 btullis: reran the `refine_eventlogging_legacy` job
- 16:56 btullis: restarted `monitor_refine_event` service on an-launcher1002 after successful refine run
- 16:55 btullis: reran refine_event for 'mediawiki_api_request|mediawiki_cirrussearch_request' at 16:40
2022-12-22
[edit]- 11:01 btullis: powering up an-presto10[05-15] but presto-server will be disabled.
2022-12-21
[edit]- 14:42 elukey: `apt-get clean` on an-launcher1002 to free some space
- 01:17 xcollazo: Deleted unused tables analytics_platform_eng.imagerec and analytics_platform_eng.imagerec_prod.
2022-12-19
[edit]- 13:45 btullis: restart presto-server on an-coord1001 to increase heap from 4GB to 16 GB T325331
- 12:11 aqu: systemctl start hadoop-namenode-backup-hdfs.service on an-master1002 at 11am UTC
- 09:36 aqu: Deployed analytics/refinery using scap, then deployed onto HDFS.
- 09:17 aqu: About to deploy analytics/refinery (bug fix in HDFS usage pipeline)
2022-12-16
[edit]- 15:36 xcollazo: deploying 'Fix subtle bug on image_suggestions when resolving varprop.' on platform_eng Airflow instance.
2022-12-15
[edit]- 22:28 btullis: run `sudo apt clean` on an-coord1001
- 19:08 xcollazo: Deploying Spark3 upgrade of image_suggestions job to the platform_eng Airflow instance.
- 10:03 joal: Restart failed airflow tasks
2022-12-13
[edit]- 21:35 aqu: Deploying analytics/refinery (HDFS FSImage conversion to XML script)
2022-12-09
[edit]- 08:38 joal: Kill refine_eventlogging_legacy stuck job (application_1663082229270_510052)
2022-12-08
[edit]- 13:55 joal: rerun webrequest failed jobs for hour 2022-12-08-T11:00Z with updated workflow (no dataloss checks)
- 12:23 joal: rerun webrequest failed jobs for hour 2022-12-08-T11:00Z
2022-12-07
[edit]- 17:57 aqu: Adding raw hdfs fsimage dir in HDFS (an-launcher1002)
- 17:47 aqu: Adding hdfs/usage folder dataset in HDFS
- 16:24 aqu: Deploying analytics/refinery (HDFS usage scripts)
- 15:13 btullis: roll-restarting AQS to pick up new mediawiki_history_reduce snapshot
- 14:06 btullis: rebuilding an-tool1005 as bullseye to test superset 1.5.2 upgrade
- 09:10 btullis: reboot an-worker1108 as it was spinning with soft CPU lockups
2022-12-06
[edit]- 12:47 btullis: sudo systemctl restart wmf_auto_restart_prometheus-mysqld-exporter.service on matomo1002
- 11:53 btullis: attempting to unmount and remount `/mnt/hdfs` on stat1004
2022-12-05
[edit]- 11:45 steve_munene: restarting presto-server.service on an-presto1007 T323783
2022-11-30
[edit]- 16:45 btullis: roll-restarting presto workers again for T321960 and T321231
- 16:20 btullis: roll-restarting presto workers for T321960 and T321231
- 16:19 btullis: restarting presto-server on an-coord1001 for T321960 and T321231
- 13:39 btullis: pushing out conda-analytics to all remaining servers `btullis@cumin1001:~$ sudo debdeploy deploy -u 2022-11-30-conda-analytics.yaml -Q P:analytics::conda_analytics`
- 13:02 btullis: deploying conda-analytics 0.0.12 to stat boxes for T321088
- 12:29 btullis: repooling eqiad for eventstreams for T324074
- 11:59 btullis: depooling eqiad for eventstreams for T324074
- 11:34 btullis: repooling codfw for eventstreams for T324074
- 11:32 btullis: destroying the eventstreams deployment in codfw and reapplying for T324074
- 11:11 btullis: depooling codfw for eventstreams for T324074
2022-11-29
[edit]- 17:12 ottomata: deploying refinery, then restarting druid webrequest daily and hourly loading oozie jobs
- 17:08 btullis: booted all of the an-worker nodes that had been switched off.
- 15:04 btullis: shutting down an-worker1093
- 15:03 btullis: shutting down an-worker1089
- 15:02 btullis: shutting down an-worker1085
- 15:00 btullis: shutting down an-worker1083
- 14:58 btullis: shutting down an-worker1079
- 14:55 btullis: shutting down an-worker1090
2022-11-28
[edit]- 12:00 btullis: restarted presto-server on an-coord1001 to test T321960
2022-11-25
[edit]- 15:29 btullis: reset the bmc on an-coord1002
- 11:24 elukey: restart turnilo on an-tool1007 to pick up new settings for webrequest_sampled_live
- 10:07 elukey: refresh the webrequest-sampled-live druid supervisor after https://gerrit.wikimedia.org/r/c/analytics/refinery/+/859463
2022-11-24
[edit]- 16:21 SandraEbele: restarted webrequest-druid-daily-coord as part of weekly deployment train.
- 16:15 SandraEbele: killed webrequest-druid-daily-coord for restart as part of weekly deployment train.
- 16:13 SandraEbele: successfully restarted webrequest-druid-hourly-coord for restart as part of weekly deployment train.
- 16:11 SandraEbele: killed webrequest-druid-hourly-coord for restart as part of weekly deployment train.
- 15:30 SandraEbele: Started deployment of refinery as part of weekly deployment train
2022-11-23
[edit]- 15:38 btullis: roll-restarting kafka-jumbo brokers to pick up new certificates. T323697
2022-11-18
[edit]- 18:56 mforns: re-ran refine_event_sanitized_analytics_immediate from 2022-11-17T13 to 2022-11-18T18 to fix the issues caused by a bug (allow-list typo) deployed yesterday.
2022-11-17
[edit]- 17:14 mforns: restarted mediawiki-denormalize-coord as part of weekly deployment train
- 16:07 mforns: finished refinery deployment
- 15:53 mforns: started refinery deployment for weekly train (accompanying refinery-source 0.2.9)
- 14:52 btullis: deploying updated hadoop packages to druid-public
- 14:51 btullis: deploying updated hadoop packages to druid-analytics
- 14:37 btullis: deploying updated hadoop packages to hue and yarn webservers
- 14:34 btullis: deploying updated hadoop packages to analytics-presto hosts
2022-11-16
[edit]- 21:40 mforns: deployed airflow up to e08e32e83b519dee214b7177bbe0fd3ac5a0be3c
- 20:37 mforns: deployed refinery-source 0.2.9 as part of weekly deployment train
- 09:11 elukey: update the webrequest sampled live supervisor on Druid Analytics after https://gerrit.wikimedia.org/r/857408
2022-11-15
[edit]- 14:24 elukey: started webrequest_sampled supervisor on Druid Analytics - T314981
- 11:50 elukey: `elukey@kafka-jumbo1001:~$ kafka topics --create --topic webrequest_sampled --partitions 3 --replication-factor 3` - T314981
2022-11-07
[edit]- 06:24 aqu: sudo systemctl reset-failed monitor_refine_eventlogging_legacy.service
- 06:00 aqu: Rerunning on an-launcher1002 sudo -u analytics kerberos-run-command analytics refine_eventlogging_legacy --ignore_failure_flag=true --table_include_regex='homepagemodule' --since='2022-11-04T15:00:00.000Z' --until='2022-11-05T16:00:00.000Z'
2022-11-04
[edit]- 10:14 btullis: btullis@clouddumps1002:/srv/dumps/xmldatadumps/public/other/pageview_complete/2022/2022-11$ sudo systemctl restart analytics-dumps-fetch-pageview_complete_dumps.service
- 10:14 btullis: btullis@clouddumps1002:/srv/dumps/xmldatadumps/public/other/pageview_complete/2022/2022-11$ sudo chown dumpsgen:dumpsgen pageviews-20221102-automated.bz2
2022-11-03
[edit]- 08:55 joal: Add _SUCCESS file to manually computed pageview-actor data for 2022-11-02T11:00
2022-10-27
[edit]- 17:24 mforns: re-running webrequest-load-wf-text-2022-10-27-10 with lower thresholds
2022-10-25
[edit]- 17:28 mforns: deployed refinery to the test cluster
2022-10-24
[edit]- 16:19 btullis: `chown analytics-deploy /srv/deployment/analytics` on clouddumps100[1-2]
- 15:30 mforns: finished deploying refinery as part of the weekly train
- 15:30 mforns: deployed airflow-dags as part of weekly train
- 15:12 mforns: starting refinery regular weekly deploy
- 07:32 elukey: `elukey@stat1005:~$ sudo systemctl reset-failed session-c4122.scope session-c4123.scope session-c4124.scope session-c4447.scope session-c4450.scope session-c4449.scope session-c4638.scope jupyter-echetty-singleuser.service`
- 07:30 elukey: `elukey@stat1004:~$ sudo systemctl reset-failed jupyter-ntsako-singleuser.service`
2022-10-23
[edit]- 13:31 elukey: clean logs with 10d+ on an-airflow1001 to free some space
- 13:26 elukey: clean logs with 15d+ on an-airflow1001 to free some space
2022-10-22
[edit]- 08:17 joal: rerun webrequest-load-wf-text-2022-10-22-3 oozie job with higher error threshold
2022-10-21
[edit]- 16:55 btullis: restarting hive-server2 service on an-coord1001
- 16:49 btullis: restarting hue on an-tool1009
- 15:18 joal: restart hive-server2 service
- 07:32 joal: restart failed oozie jobs
- 07:28 joal: Restart HiveServer2 on an-coord1001 (I didn't even know I could do this)
- 06:53 joal: killing old mjolnit jobs
- 06:50 joal: Kill rerun stuck oozie job
- 06:37 joal: Kill skein test jobs in arn
2022-10-19
[edit]- 17:14 btullis: reset the BMC on analytics1075
2022-10-17
[edit]- 18:17 mforns: deleted Airflow DAGs for backfilling of Cassandra loading of unique devices
2022-10-15
[edit]- 09:24 joal: Rerun failed refine_eventlogging_analytics job
- 09:00 joal: Rerun pageview-hourly-wf-2022-10-14-23
2022-10-13
[edit]- 13:43 mforns: cleared airflow job wikidata_dump_to_hive_weekly
2022-10-12
[edit]- 15:26 ottomata: remove materialized .json files from schemas/event/primary - this should be a no-op as no clients should actually be using the json files. - T315674
2022-10-11
[edit]- 15:44 ottomata: remove materialized .json files from schemas/event/secondary - this should be a no-op as no clients should actually be using the json files. - T315674
- 15:04 btullis: reset the BMC on an-worker1086 with `sudo bmc-device --cold-reset`
- 06:44 elukey: kill leftover process of jmads on stat1005 to allow user cleanup via puppet
- 06:43 elukey: kill leftover process of nokafor on stat1004 to allow user cleanup via puppet
- 06:37 elukey: kill leftover process of bmansurov on stat1007 to allow user cleanup via puppet
- 06:34 elukey: kill leftover process of bmansurov on an-airflow1002 to allow user cleanup via puppet
2022-10-10
[edit]- 15:36 mforns: reran geoeditors_public_monthly airflow DAG for Sept 2022, after fix
- 15:34 mforns: deployed airflow to fix geoeditors_public_monthly DAG
- 15:31 mforns: started unique devices daily back-filling in cassandra from 1st of July to end of Sept
2022-10-08
[edit]- 11:48 joal: rerun webrequest-load-wf-text-2022-10-7-20
2022-10-07
[edit]- 09:26 elukey: delete calico pods in CrashLoop on dse (probably due to the incorrect docker settings)
- 07:54 elukey: re-initialize docker on dse-k8s-worker1004 - wrong storage type set (devicemapper instead of overlay2)
- 07:49 elukey: re-initialize docker on dse-k8s-worker100[5-8] - wrong storage type set (devicemapper instead of overlay2)
2022-10-06
[edit]- 19:51 SandraEbele: Started airflow projectview_hourly_dag
- 19:51 SandraEbele: Killed Oozie projectview-hourly job
- 19:40 SandraEbele: Deployed airflow to fix projectview_hourly_dag
- 13:48 btullis: decommission aqs1007 (also forgot to log aqs1006)
- 12:15 btullis: decommissioning aqs1005
- 11:23 btullis: decommissioning aqs1004
2022-10-05
[edit]- 16:48 btullis: forcibly and lazily unmounted legacy labstore hosts from an-launcher1002 and removed their /etc/fstab entries
- 15:27 SandraEbele: deployed refinery source
- 14:33 mforns: finished refinery deploy - regular weekly train
- 14:05 mforns: starting refinery deploy - regular weekly train
- 13:49 SandraEbele: Started Airflow projectview_geo job
- 13:48 SandraEbele: killed Oozie projectview-geo-coord job
- 13:21 SandraEbele: deploying fix for projective tags on airflow.
2022-10-04
[edit]- 09:53 btullis: deployed eventgate-logging-external to eqiad (a few minutes ago)
- 09:45 btullis: deploying new eventgate-logging-external service to codfw
- 09:44 btullis: deploying new eventgate-logging-external service to staging
2022-10-02
[edit]- 08:13 elukey: apt-get clean on an-airflow1001 to free some space on the root partition
2022-09-30
[edit]- 08:41 btullis: restarted hive-server2 and hive-metastore services on an-coord1002 (standby) server
2022-09-29
[edit]- 12:34 joal: Rerun failed oozie webrequest-load-wf-text-2022-9-29-9
- 06:38 joal: Try to rerun airflow unique_devices_daily.compute_per_project_family_metrics.2022-09-15
- 06:37 joal: Rerun airflow unique_devices_dailyschedule: @daily
2022-09-28
[edit]- 19:50 mforns: killed oozie's unique_devices-per_domain-daily-coord because we migrated it to airflow
- 19:49 mforns: killed oozie's unique_devices-per_project_family-daily-coord because we migrated it to airflow
- 19:48 mforns: killed oozie's unique_devices-per_project_family-monthly-coord because we migrated it to airflow
- 19:48 mforns: killed oozie's unique_devices-per_domain-monthly-coord because we migrated it to airflow
- 18:22 mforns: deployed airflow to fix unique_devices jobs
- 15:29 SandraEbele: started airflow projectview_geo job
- 15:01 btullis: roll-restarting druid-analytics
- 15:00 SandraEbele: deploying Airflow for hdfsarchiver operator fix
- 14:02 btullis: roll-restarting druid-public
- 09:22 btullis: started cookbook sre.kafka.roll-restart-brokers jumbo-eqiad
2022-09-27
[edit]- 15:05 mforns: re-ran wikidata_metrics_to_graphite_daily failed airflow tasks
- 15:03 mforns: re-ran cassandra_daily_load failed airflow tasks
- 14:59 mforns: re-ran apis_metrics_to_graphite_hourly
- 14:56 mforns: deployed Airflow (fixed)
- 14:23 mforns: rolled back Airflow
- 14:23 mforns: deployed Airflow for 3 fixes
2022-09-26
[edit]- 20:07 xcollazo: Kill oozie geoeditors jobs for load, public monthly, and yearly after Airflow migration.
- 16:13 joal: rerunning failed webrequest-text-2022-09-26-15
- 13:48 aqu: Deploying airflow-dags on analytics & analytics_test
- 11:03 btullis: failing back hive to an-coord1001 using DNS https://gerrit.wikimedia.org/r/c/operations/dns/+/832294
- 09:41 btullis: rebooted matomo1002 at the VM level to pick up new disk
- 09:40 btullis: merged the spark3 patch https://gerrit.wikimedia.org/r/c/operations/puppet/+/834500
- 06:36 elukey: clean up my old home dir on matomo1002, ran `apt-get clean` + some other clean up steps on matomo1002 to free space on the root partition
2022-09-23
[edit]- 19:11 mforns: deployed Airflow analytics for a quick fix
2022-09-22
[edit]- 22:26 joal: Kill oozie cassandra monthly loading jobs as we migrate them to airflow
- 22:20 joal: Deploy airflow for cassandra-loading patch
- 20:53 joal: Deploy analytics airflow-dags to try to fix cassandra loading jobs
2022-09-21
[edit]- 19:25 joal: Kill oozie daily cassandra loading jobs as we move them to airflow
- 19:18 ottomata: kill aarora process 30421 run_embedding_training.sh on stat1005
- 19:13 joal: Deployed refinery for HQL patch (Njideka)
- 19:11 ottomata: kill aarora process 14584 on stat1005 - using 2500% cpu
2022-09-20
[edit]- 20:10 mforns: finished refinery deployment (weekly train)
- 19:55 mforns: starting refinery deployment (weekly train)
- 15:45 joal: kill oozie hourly cassandra loading job (1 job) in favor of the airflow one
2022-09-19
[edit]- 22:28 milimetric: Wikistats: improved build a little and deployed fix to T312717
2022-09-15
[edit]- 08:43 aqu: about to deploy analytics/refinery
- 05:14 aqu: sudo -u analytics kerberos-run-command analytics refine_eventlogging_legacy --table_include_regex='wikipediaportal' --since='2022-09-13T23:00:00.000Z' --until='2022-09-15T00:00:00.000Z'
2022-09-14
[edit]- 17:11 aqu: Sep 14 15:23:34 UTC sudo systemctl start check_webrequest_partitions.service
- 12:56 aqu: ~1hago sudo systemctl start refinery-sqoop-mediawiki-production-daily.service ; sudo systemctl start refinery-import-siteinfo-dumps.service ; sudo systemctl start refinery-import-page-current-dumps.service ; sudo systemctl start refinery-import-page-history-dumps.service
- 11:34 btullis: remounted all remaining /mnt/hdfs mount points, except stat1005 which is busy
- 11:12 btullis: remounted /mnt/hdfs on an-coord100[1-2]
- 11:09 btullis: remounted /mnt/hdfs on an-airflow1001
- 09:14 joal: Restart oozie virtualpageview job
- 09:10 btullis: re-mounted /mnt/hdfs on an-launcher1002.
- 07:11 joal: restart webrequest oozie bundle
2022-09-13
[edit]- 17:22 joal: rerun refine_eventloggin_legacy
- 17:14 joal: rerun refine_event
- 17:14 joal: rerun refine_netflow
- 16:53 joal: Rerun refine_eventlogging_analytics
- 16:45 joal: Kill-rerun suspended oozie jobs (virtual-pagview and predictions-actor
- 16:34 joal: rerun failed webrequest oozie jobs
- 16:30 btullis: restarting hive-server2 and hive-metastore on an-coord1001 (currently standby)
- 16:29 btullis: restarting oozie on an-coord1001
- 16:10 joal: Rerun failed oozie webrequest jobs
- 15:57 btullis: rolling out updated hadoop packages to an-airflow1003
- 15:55 btullis: rolling out upgraded hadoop client packages to stat servers.
- 15:51 btullis: restarting eventlogging_to_druid_network_flows_internal_hourly.service eventlogging_to_druid_prefupdate_hourly.service refine_event_sanitized_analytics_immediate.service refine_event_sanitized_main_immediate.service
- 15:49 btullis: restarting eventlogging_to_druid_navigationtiming_hourly.service on an-launcher1002
- 15:46 btullis: restarting eventlogging_to_druid_editattemptstep_hourly.service on an-launcher1002
- 15:44 btullis: cancel that last message. Upgrading hadoop packages on an-launcher instead. They were inadvertently omitted last time.
- 15:39 btullis: Going to downgrade hadoop on ann hadoop-worker nodes to 2.10.1
- 15:21 btullis: failed over hive to an-coord1002 via DNS https://gerrit.wikimedia.org/r/c/operations/dns/+/831906
- 15:20 btullis: restarted yarn service on an-master1002 to make the active host an-master1001 again.
- 15:11 btullis: restart hive-server2 and hive-metastore service on an-coord1002 to pick up new version of hadoop
- 14:55 btullis: rolling out updated hadoop packages to analytics-airflow (cumin alias) hosts
- 14:42 btullis: sudo systemctl restart analytics-reportupdater-logs-rsync.service on an-launcher1002
- 13:21 joal: Manual launch of refinery-drop-mediawiki-snapshots with new tables in patch https://gerrit.wikimedia.org/r/831866
- 10:51 btullis: attempting failback operation on hadoop namenodes
- 09:42 btullis: roll-restarting the hadoop masters via the cookbook
2022-09-12
[edit]- 08:37 btullis: cold-reset BMC device on analytics1073
2022-09-08
[edit]- 17:32 joal: make ops reboot stat1008
2022-09-07
[edit]- 13:36 joal: rerun failed airflow tasks
2022-09-06
[edit]- 22:18 milimetric: restarted webrequest druid daily and hourly jobs
- 22:18 milimetric: restarted referrer daily coordinator
- 22:18 milimetric: restarted webrequest load bundle
- 21:57 milimetric: finished cleaning up bad state and re-deploying refinery
- 21:45 milimetric: cleared logs earlier than September 1st from an-launcher1002:/srv/airflow-analytics/logs/scheduler
- 18:49 milimetric: finished refinery-source 0.2.6 deploy, waiting 5 minutes and starting refinery deploy
- 18:28 milimetric: weekly deployment train starting
- 09:55 btullis: merged and deployed https://gerrit.wikimedia.org/r/c/operations/puppet/+/821695
2022-09-04
[edit]- 12:49 elukey: pkill remaining processes of user effeietsanders on stat1008 to unblock puppet
2022-09-02
[edit]- 08:25 joal: Restart mediawiki_history_denormalize job manually
2022-08-30
[edit]- 17:49 joal: Deploying refinery onto HDFS
- 17:11 joal: deploy refinery using scap
- 17:11 joal: release refinery-source v0.2.5 to archiva
2022-08-29
[edit]- 16:44 mforns: killed mediawiki-history-dumps oozie after migration to airflow
- 08:04 joal: Rerun refine_eventlogging_legacy failed hours
- 07:54 joal: rerun pageview-hourly-wf-2022-8-28-15 oozie workflow
2022-08-22
[edit]- 16:25 btullis: btullis@an-airflow1004:~$ sudo systemctl reset-failed ifup@ens13.service
2022-08-19
[edit]- 08:45 btullis: restarted archiva to pick up new JRE
2022-08-18
[edit]- 19:57 ottomata: apply yarn production queue changes to allow analytics-research and analytics-platform-eng users to submit jobs to production queue - T312858
- 14:04 btullis: re-running refine_eventlogging_legacy for helppanel
- 09:51 btullis: restarted monitor-refine-event on an-launcher1002
2022-08-17
[edit]- 13:19 mforns: deployed airflow for https://gitlab.wikimedia.org/repos/data-engineering/airflow-dags/-/merge_requests/117
2022-08-16
[edit]- 18:49 ottomata: complete refinery deploy that was unfinished from last week. an-launcher1002 and hdfs already have this version (6e47e0e712528c8816b7fd7456b8745e4dbc5c72) deployed.
- 16:02 btullis: deploying airflow-dags
2022-08-15
[edit]- 19:26 ottomata: test
2022-08-10
[edit]- 18:04 ottomata: Deployed refinery using scap, then deployed onto hdfs
- 17:03 ottomata: stopping puppet and drop data timers on an-launcher1002 and an-test-coord1001 to deploy drop script changes - T270433
- 13:42 btullis: failed hive back to an-coord1001 via DNS change.
- 11:47 btullis: btullis@an-coord1001:~$ sudo systemctl restart hive-server2.service hive-metastore.service
2022-08-08
[edit]- 11:43 btullis: rebooting an-worker1102 due to kernel soft lockups
2022-08-05
[edit]- 16:05 milimetric: force scap deploying refinery
- 16:01 ottomata: removing airflow logs older than 7 days on an-launcher1002
2022-08-04
[edit]- 18:31 ottomata: dropping medawiki_web_ui_interactions hive tables and data - T314151
- 18:19 milimetric: scap deploying refinery host by host after Ben cleaned up the repos with "git checkout master"
- 18:11 btullis: btullis@deploy1002:/srv/deployment/analytics/refinery$ scap deploy -l stat1008.eqiad.wmnet "Regular analytics weekly train [analytics/refinery@$(git rev-parse --short HEAD)]"
- 18:05 btullis: we are re-deploying refinery to an-launcher1002 with the command above
- 18:04 btullis: btullis@deploy1002:/srv/deployment/analytics/refinery$ scap deploy -l an-launcher1002.eqiad.wmnet "Regular analytics weekly train [analytics/refinery@$(git rev-parse --short HEAD)]"
- 18:02 btullis: analytics-deploy@an-launcher1002:/srv/deployment/analytics/refinery$ git checkout master
- 15:59 SandraEbele: Deploying analytics refinery using scap.
2022-08-02
[edit]- 12:54 btullis: sudo systemctl reset-failed on stat1008 to remove failed debmonitor alerts
2022-07-28
[edit]- 20:05 SandraEbele: killing Oozie projectview-hourly and projectview-geo jobs to deploy corresponding jobs on airflow.
2022-07-24
[edit]- 21:10 btullis: swapping disks on archiva1002
- 20:36 btullis: rebooting archiva1002 to pick up new disk
- 15:36 btullis: btullis@ganeti1027:~$ sudo gnt-instance modify --disk add:size=200g archiva1002.wikimedia.org
2022-07-22
[edit]- 21:19 ottomata: restarted airflow-scheduler@platform_eng on an-airflow1003 for marco and cormac
2022-07-19
[edit]- 10:05 elukey: reboot an-worker1127 - hdfs datanode caused CPU stalls
2022-07-13
[edit]- 14:19 aqu: Deployed refinery using scap, then deployed onto hdfs (prod + test)
- 06:16 aqu: analytics/refinery deployment
2022-07-07
[edit]- 13:38 btullis: restart refine_eventlogging_legacy_test.service on an-test-coord1001
- 09:56 btullis: restarted oozie on an-test-coord1001
- 09:23 btullis: rebooted dbstore1007
- 09:21 btullis: rebooted dbstore1005
- 09:02 btullis: restarting dbstore1003 as per announced maintenance window
2022-07-06
[edit]- 18:09 ottomata: enabling iceberg hive catalog connector on analytics_cluster presto
- 17:57 ottomata: upgrading presto to 0.273.3 in analytics cluster - T311525
- 09:50 btullis: roll-restarting hadoop workers on the test cluster.
- 09:46 btullis: restarting refinery-drop-webrequest-raw-partitions.service on an-test-coord1001
- 09:44 btullis: restarting refinery-drop-webrequest-refined-partitions.service on an-test-coord1001
- 09:42 btullis: restarted drop_event.service on an-test-coord1001
- 09:35 btullis: restarting hive-server2 and hive-metastore on an-test-coord1001
2022-07-05
[edit]- 11:01 btullis: sudo cookbook sre.hadoop.roll-restart-masters test
2022-07-04
[edit]- 16:14 btullis: systemctl restart airflow-scheduler@research.service (on an-airflow1002)
- 08:04 elukey: kill leftover processes of user `mewoph` on stat100x to allow puppet runs
2022-06-29
[edit]- 17:27 mforns: killed mediawiki-history-load bundle in Hue, and started corresponding mediawiki_history_load DAG in Airflow
- 13:12 mforns: re-deployed refinery with scap and refinery-deploy-to-hdfs
- 11:51 btullis: btullis@an-master1001:~$ sudo -u hdfs /usr/bin/hdfs haadmin -failover an-master1002-eqiad-wmnet an-master1001-eqiad-wmnet
2022-06-28
[edit]- 20:57 mforns: refinery deploy failed and I rolled back successfully, will try and repeat tomorrow when other people are present :]
- 20:19 mforns: starting refinery deployment for refinery-source v0.2.2
- 20:19 mforns: starting refinery deploymenty
- 17:25 ottomata: installing presto 0.273.3 on an-test-coord1001 and an-test-presto1001
- 12:48 milimetric: deploying airflow-dags/analytics to work on the metadata ingestion jobs
2022-06-27
[edit]- 20:33 btullis: systemctl reset-failed jupyter-aarora-singleuser and jupyter-seddon-singleuser on stat1005
- 20:16 btullis: checking and restarting prometheus-mysqld-exporter on an-coord1001
- 15:25 btullis: upgraded conda-base-env on an-test-client1001 from 0.0.1 to 0.0.4
2022-06-24
[edit]- 15:14 ottomata: backfilled eventlogging data lost during failed gobblin job - T311263
2022-06-23
[edit]- 13:48 btullis: started the namenode service on an-master1001 after failback failure
- 13:41 btullis: The failback didn't work again.
- 13:39 btullis: attempting failback of namenode service from an-master1002 to an-master1001
- 13:07 btullis: restarted hadoop-hdfs-namenode service on an-master1001
- 11:25 joal: kill oozie mediawiki-geoeditors-monthly-coord in favor of airflow job
- 08:52 joal: Deploy airflow
2022-06-22
[edit]- 20:55 aqu: `scap deploy -f analytics/refinery` because of a crash during `git-fat pull`
- 19:30 aqu: Deploying analytics/refinery
2022-06-21
[edit]- 14:56 aqu: RefineSanitize from an-launcher1002: sudo -u analytics kerberos-run-command analytics spark2-submit --class org.wikimedia.analytics.refinery.job.refine.RefineSanitize --master yarn --deploy-mode client /srv/deployment/analytics/refinery/artifacts/org/wikimedia/analytics/refinery/refinery-job-0.1.15.jar --config_file /home/aqu/refine.properties --since "2022-06-19T09:52:00+0000" --until
- 13:33 aqu: sudo systemctl start monitor_refine_event_sanitized_main_immediate.service on an-launcher1002
- 10:47 btullis: proceeding with the hadoop.roll-restart-masters cookbook
2022-06-20
[edit]- 07:14 SandraEbele: Started Airflow 3 Wikidata metrics jobs (Articleplaceholder, Reliability and SpecialEntityData metrics).
- 07:12 SandraEbele: Started Airflow3 Wikidata metrics jobs (Articleplaceholder, Relia)
- 07:11 SandraEbele: killed Oozie wikidata-articleplaceholder_metrics-coord, wikidata-reliability_metrics-coord, and wikidata-specialentitydata_metrics-coord jobs.
2022-06-17
[edit]- 12:35 SandraEbele: deployed daily airflow dag for 3 Wikidata metrics.
- 08:36 btullis: power cycled an-worker1109 as it was stuck with CPU soft lockups
2022-06-16
[edit]- 06:49 joal: Rerun webrequest-load-wf-upload-2022-6-15-22 after weird oozie failure
2022-06-15
[edit]- 14:48 btullis: deploying datahub 0.8.38
2022-06-14
[edit]- 10:48 joal: unpause renamed dags
- 10:44 joal: Deploy Airflow
- 10:12 btullis: manually failing back hdfs-namenode to an-master1001 after fixing typo
- 09:36 joal: deploy refinery onto HDFS
- 08:48 btullis: roll-restarting hadoop masters T310293
- 08:40 joal: Deploying using scap again after failure cleanup on an-launcher1002
- 07:45 joal: deploy refinery using scap
2022-06-13
[edit]- 14:00 btullis: restarting presto service on an-coord1001
- 13:20 btullis: btullis@datahubsearch1001:~$ sudo systemctl reset-failed ifup@ens13.service T273026
- 13:09 btullis: restarting oozie service on an-coord1001
- 12:59 btullis: havaing failed over hive to an-coord1002 10 minutes ago, I'm restarting hive services on an-coord1001
- 12:26 btullis: restarting hive-server2 and hive-metastore on an-coord1002
- 09:54 joal: rerun failed refine for network_flows_internal
- 09:54 joal: Rerun failed refine for mediawiki_talk_page_edit events
- 09:51 joal: Manually rerun webrequest_text laod for hour 2022-06-13T03:00
- 07:18 joal: Manually rerun webrequest_text laod for hour 2022-06-12T08:00
2022-06-10
[edit]- 17:00 ottomata: applied change to airflow instances to bump scheduler parsing_processes = # of cpu processors
- 08:58 btullis: cookbook sre.hadoop.roll-restart-workers analytics
2022-06-09
[edit]- 17:17 joal: Rerun refine for failed datasets
- 14:15 btullis: manually failing back HDFS namenode from an-master1002 to an-master1001
- 13:15 btullis: roll-restarting the hadoop masters to pick up new JRE
2022-06-08
[edit]- 18:06 joal: Restart airflow after deploy for dag reprocessing
- 18:02 joal: deploying Airflow dags
- 13:45 btullis: deploying refinery
2022-06-07
[edit]- 13:45 btullis: deploying updated eventgate images to all remaining deployments.
- 11:33 btullis: deployed an updated version of eventgate to eventgate-analytics-external to address the timing mis-calculation.
- 10:51 btullis: restart the eventlogging_to_druid_netflow-sanitization_daily service on an-launcher1002
2022-06-06
[edit]- 13:45 btullis: restarting archiva service for new JRE
- 06:31 elukey: restart memcached on an-tool1005 to pick up puppet settings and clear an alert in icinga
2022-06-05
[edit]- 03:14 milimetric: rerunning mw history since the last failure just looked like a fluke
2022-06-04
[edit]- 11:41 joal: Maunally launch refinery-sqoop-mediawiki-production after manual fix of refinery-sqoop-mediawiki
- 11:39 joal: Manually sqoop enwiki:user and commonswiki:user and add _SUCCESS flag for following job to kick off
2022-06-02
[edit]- 15:50 mforns: deployed wikistats 2.9.5
- 14:02 joal: Start browser_general_daily on airflow
- 13:19 joal: Drop and recreate wmf_raw.mediawiki_page table (field removal)
- 12:44 joal: Remove wrongly formatted interlanguage data
- 12:36 joal: Kill interlanguage-daily oozie job after successfull move to airflow
- 12:15 joal: Deploy interlanguage fix to airflow
- 09:56 joal: Relaunch sqoop after having deployed a corrective patch
- 09:46 joal: Manually mark interlaguage historical tasks failed in airflow
- 08:54 joal: Deploy airflow with spark3 jobs
- 08:47 joal: Merging 2 airflow spark3 jobs now that their refinery counterpart is dpeloyed
- 08:07 joal: Deploy refinery onto HDFS
- 07:26 joal: Deploy refinery using scap
2022-06-01
[edit]- 21:04 milimetric: trying to rerun sqoop from a screen on an-launcher
- 20:09 SandraEbele: Successfully deployed refinery using scap, then deployed onto hdfs.
- 18:51 SandraEbele: About to deploy analytics/refinery (regular weekly train)
- 08:39 elukey: powercycle an-worker1094 - OEM event registered in `racadm getsel`, host frozen
2022-05-31
[edit]- 18:48 ottomata: sudo -u hdfs hdfs dfsadmin -safemode leave on an-master1001
- 18:12 ottomata: sudo service hadoop-hdfs-namenode start on an-master1002
- 18:10 ottomata: sudo -u hdfs hdfs dfsadmin -safemode enter
- 17:47 btullis: starting namenode services on am-master1001
- 17:44 btullis: restarting the datanodes on all five of the affected hadoop workers.
- 17:43 btullis: restarting journalnode service on each of the five hadoop workers with journals.
- 17:41 btullis: resizing each journalnode with resize2fs
- 17:38 btullis: sudo lvresize -L+20G analytics1069-vg/journalnode
- 17:38 btullis: increasing each of the hadoop journalnodes by 20 GB
- 17:33 ottomata: stop journalnodes and datanodes on 5 hadoop journalnode hosts
- 17:30 btullis: stopped the hdfs-namenode service on an-master100[1-2]
- 15:36 milimetric: dropped razzi databases and deleted HDFS directories (in trash)
- 06:26 elukey: `elukey@an-master1001:~$ sudo systemctl reset-failed hadoop-clean-fairscheduler-event-logs.service`
2022-05-30
[edit]- 20:19 SandraEbele: Restarted oozie job pageview-druid-daily-coord
- 11:28 joal: deploy airflow spark3 aqs_hourly
2022-05-25
[edit]- 21:09 joal: Resume aqs_hourly job in airflow test
- 20:33 joal: Pausing aqs_hourly job in airflow test intil we fix the spark3 issue
- 06:20 elukey: `elukey@an-tool1011:~$ sudo systemctl reset-failed ifup@ens13.service` - T273026
2022-05-24
[edit]- 19:54 SandraEbele: Deployed refinery using scap, then deployed onto hdfs successfully.
- 18:34 SandraEbele: Deploying refinery, regular weekly deployment
- 13:18 joal: Release refinery-source v0.2.0 to archiva
- 10:21 btullis: restarted hadoop-yarn-nodemanager on an-worker1139
2022-05-23
[edit]- 18:27 mforns: killed mobile_apps-session_metrics-coord (Airflow job is taking over)
2022-05-21
[edit]- 15:52 joal: Kill yarn app application_1651744501826_83884 in order to prevent the HDFS alerts
2022-05-19
[edit]- 16:59 ottomata: deploying airflow-dags analytics with new artifact names, first clearing artifacts cache dir - T307115
2022-05-18
[edit]- 10:57 btullis: upgrading datahub to version 0.8.34
2022-05-17
[edit]- 21:32 razzi: sudo systemctl reset-failed ifup@ens13.service on an-tool1007
- 08:54 btullis: booted an-tool1007 from network to begin buster upgrade
2022-05-12
[edit]- 14:49 razzi: undo the 2 previous confctl changes to repool dbproxy1019 to wikireplicas-b only
- 14:35 razzi: razzi@cumin1001:~$ sudo confctl select service=wikireplicas-a,name=dbproxy1019.eqiad.wmnet set/pooled=yes # for T298940
2022-05-11
[edit]- 18:20 razzi: disregard the above log; wrote out the command but then saw there was a warning for cr2-eqiad
- 18:15 razzi: razzi@lvs1019:~$ systemctl stop pybal.service to apply change https://gerrit.wikimedia.org/r/c/operations/puppet/+/779915
- 18:06 razzi: razzi@lvs1020:~$ systemctl stop pybal.service to apply change https://gerrit.wikimedia.org/r/c/operations/puppet/+/779915
- 13:29 mforns: restarted oozie jobs after deployment: mediarequest_top_files, pageview_top_articles, unique_devices_per_domain_monthly, unique_devices_per_project_family_monthly
2022-05-10
[edit]- 20:32 mforns: finished refinery deploy (regular weekly train)
- 19:34 mforns: starting refinery deploy (regular weekly train)
2022-05-09
[edit]- 15:06 SandraEbele: killed ‘apis-coord' oozie job and started corresponding airflow job ‘apis_metrics_to_graphite’
2022-05-06
[edit]- 09:11 joal: kill cassandra-monthly-wf-local_group_default_T_mediarequest_top_files-2022-4 again
- 08:44 joal: Rerun cassandra-monthly-wf-local_group_default_T_mediarequest_top_files-2022-4 with SRE watching network
- 08:29 joal: kill cassandra-monthly-wf-local_group_default_T_mediarequest_top_files-2022-4 as it was probably saturating network
2022-05-05
[edit]- 18:53 btullis: restarting airflow-scheduler@platform_eng.service on an-airflow1003
- 18:53 btullis: restarted airflow-scheduler@research.service on an-airflow1002
- 18:49 btullis: restarting airflow-scheduler@analytics service on an-launcher1002
- 12:26 aqu: Regular analytics weekly train [analytics/refinery@cc4b2bd]
- 09:53 btullis: roll-restarting hadoop masters to pick up new heap size
- 09:16 btullis: re-enabling gobblin jobs now
- 09:15 btullis: restarting failed eventlogging_to_druid_ services on an-launcher1002
- 09:00 btullis: restarting an-coord1001
- 08:53 btullis: stopping oozie on an-coord1001
2022-05-04
[edit]- 08:47 btullis: rebooting an-coord1002 to pick up new kernel
2022-05-03
[edit]- 18:24 razzi: remove /etc/apache2/sites-available/50-superset-wikimedia-org.conf from an-tool1005 (superset staging) since it was removed from puppet but has no ensure: absent
2022-04-27
[edit]- 19:37 ottomata: restarting airflow services on all airflow instances after installing updated airflow debian package
2022-04-26
[edit]- 19:02 aqu: About to deploy analytics/refinery: Weekly deployment train + Artifacts to 0.1.27
- 12:02 joal: Rerun cassandra-daily-wf-local_group_default_T_mediarequest_per_file-2022-4-23
2022-04-25
[edit]- 20:09 ottomata: dropping event.ios_notification_interaction hive table and data for backwards incompatible schema change in T290920
- 11:51 btullis: failing back hdfs active role to an-master1001
- 11:49 btullis: restarted hadoop-yarn-resourcemanager on an-master1002 to force the active role back to an-master1001
- 11:01 btullis: rebooting an-master1001
- 10:25 btullis: restarting the `check_webrequest_partitions` service on an-launcher1002
- 09:39 btullis: failover to an-master1002 successful at 3rd attempt
- 09:30 btullis: 2nd attempt to switch HDFS services to an-master1002
- 09:13 btullis: switching HDFS services to an-master1002
- 08:53 btullis: rebooting an-master1002 - T304938
2022-04-23
[edit]- 09:38 elukey: `apt-get clean` on an-airflow1001 to free some space
2022-04-21
[edit]- 22:26 mforns: killed browser_general oozie job and started corresponding airflow job
2022-04-13
[edit]- 16:40 razzi: reboot an-launcher1002 for security updates
2022-04-12
[edit]- 22:12 milimetric: deployed and synced refinery-source 0.1.26 to hdfs
2022-04-11
[edit]- 12:35 aqu: About to deploy analytics/refinery "Migrate mediarequest hourly from Oozie to Airflow" (replace previous msg)
- 12:35 aqu: About to deploy refinery/source "Migrate mediarequest hourly from Oozie to Airflow"
2022-04-06
[edit]- 20:53 razzi: roll restart aqs to deploy new mediawiki history snapshot
- 15:51 mforns: deployed airflow to analytics (big refactor)
- 15:23 mforns: deployed Airflow to analytics_test (big refactor)
- 09:18 btullis: restarted eventlogging_to_druid_netflow_hourly on an-launcher1002
2022-04-05
[edit]- 20:41 razzi: deploying refinery for https://gerrit.wikimedia.org/r/c/analytics/refinery/+/776269/
- 15:54 razzi: razzi@cumin1001:~$ sudo cookbook sre.hosts.reimage --os bullseye -t T299481 dbstore1005
- 15:10 razzi: razzi@cumin1001:~$ sudo cookbook sre.hosts.reimage --os bullseye -t T299481 dbstore1003
- 15:02 razzi: set dbstore1003.eqiad.wmnet to downtime for upgrade T299481
- 15:01 razzi: set dbstore1003.eqiad.wmnet to downtime for upgrade
2022-04-01
[edit]- 09:05 btullis: restarted varnishkafka-eventlogging.service on cp3050 T300246
2022-03-29
[edit]- 20:08 joal: rerun cassandra editors_bycountry_monthly for month 2022-02
- 20:08 mforns: restarted webrequest bundle
- 19:57 mforns: restarted mediawiki-geoeditors-public_monthly-coord
- 19:56 mforns: finished refinery deployment (regular weekly train) scap and hdfs
- 19:53 joal: Add new columns to wmf.webrequest (high entropy CH-UA)
- 19:16 joal: Drop/recreate wmf_raw.webrequest for schema change (high-entropy CH-UA)
- 19:13 mforns: starting refinery deployment (regular weekly train)
- 19:11 joal: kill webrequest-load oozie bundle for webrequest schema change
- 17:13 razzi: razzi@cumin1001:~$ sudo cookbook sre.hosts.downtime an-tool1005.eqiad.wmnet -D 1 -r 'Testing deploy of superset 1.4.2 to staging'
- 15:38 ntsako: Stopped geoeditor Airflow DAGs to check on data quality
- 14:13 btullis: correction: restarted hadoop-yarn-nodemanager.service on an-worker1128
- 14:13 btullis: restarted hadoop-yarn-nodemanager.service on an-worker1238
2022-03-24
[edit]- 11:15 btullis: roll-restarting kafka-jumbo brokers T300626
2022-03-21
[edit]- 18:10 razzi: sudo systemctl restart jupyter-bearloga-singleuser on stat1008
2022-03-17
[edit]- 17:10 ottomata: restart webrequest and pageview_actor data purge - https://gerrit.wikimedia.org/r/c/operations/puppet/+/771389
- 14:07 btullis: shutdown analytics1063 and analytics1067 with 120 minutes of downtime T303151
- 06:46 elukey: kill remaining hanging processes for ppche*lko and accra*ze on an-test-client1001 to allow users offboard (puppet broken)
2022-03-16
[edit]- 19:14 ottomata: deploying refinery to hadoop-test cluster with new gobblin-wmf-core jar
- 18:00 razzi: sudo cookbook sre.hosts.downtime -D 3 -r 'Setting up karapace for the first time' karapace1001.eqiad.wmnet
- 17:57 btullis: restarted mediawiki-history-drop-snapshot service on an-launcher1002
- 16:03 aqu: analytics/refinery - scap deply "Migrate session_length/daily from Oozie to Airflow"
- 10:26 btullis: rerunning failed mediawiki_structured_task_article_link_suggestion_interaction refnie job
2022-03-15
[edit]- 22:16 razzi: upload karapace_2.1.3-py3.7-1_amd64.deb to apt.wikimedia.org
- 19:58 razzi: upload karapace_2.1.3-py3.7-0_amd64.deb to apt.wikimedia.org
- 17:24 ottomata: also change stats uid and gid to 918 on an-web1001 - T291384
- 14:35 ottomata: change stats uid and gid on all stat boxes to 918 - T291384
- 13:59 ottomata: roll restarting kafka jumbo brokers to set max.incremental.fetch.session.cache.slots=2000 - T303324
2022-03-14
[edit]- 21:05 razzi: `sudo kill -9 15674` to stop unresponsive hive query
2022-03-09
[edit]- 21:05 ottomata: fix group ownership of cchen.db/new_editors/cohort=2021-12 after reverting T291664 - sudo -u hdfs kerberos-run-command hdfs hdfs dfs -chgrp -R analytics-privatedata-users /user/hive/warehouse/cchen.db/new_editors/cohort=2021-12
- 18:33 ottomata: fix group ownership of wmf_product.db//new_editors/cohort=2021-12 after reverting T291664 - sudo -u hdfs kerberos-run-command hdfs hdfs dfs -chgrp -R analytics-privatedata-users /user/hive/warehouse/wmf_product.db/new_editors/cohort=2021-12
- 18:32 ottomata: fix group ownership of wmf_product.db/global_markets_pageviews/year=2022/month=2 after reverting T291664 - sudo -u hdfs kerberos-run-command hdfs hdfs dfs -chgrp -R analytics-privatedata-users /user/hive/warehouse/wmf_product.db/global_markets_pageviews/year=2022/month=2
- 18:19 btullis: btullis@ganeti1024:~$ sudo gnt-instance start karapace1001.eqiad.wmnet (T301562)
- 16:16 ottomata: fix group ownership of wmf_product.db/poageviews_corrected/year=222/month=2 after reverting T291664 - sudo -u hdfs kerberos-run-command hdfs hdfs dfs -chgrp -R analytics-privatedata-users /user/hive/warehouse/wmf_product.db/pageviews_corrected/year=2022/month=2
2022-03-08
[edit]- 13:31 ottomata: restarted webrequest-load oozie bundle as 0073173-220113112502223-oozie-oozi-B starting at 2022-03-08T12:00Z
- 13:09 ottomata: killing and rerunning webrequest-load-text-wf for webrequest_source=text/year=2022/month=3/day=7/hour=17, it was stuck in add_partition task as SUSPENDED, not sure why.
- 12:47 btullis: roll-restarting druid-analytics T300626
- 12:08 btullis: roll-restarting druid-public. T300626
- 11:21 btullis: roll-restarting druid-test T300626
- 11:00 btullis: roll-restarting aqs T300626
- 10:57 btullis: restarted archiva T300626
2022-03-07
[edit]- 19:14 ottomata: sudo -u hdfs kerberos-run-command hdfs hdfs dfs -chgrp -R analytics-privatedata-users /wmf/data/wmf/*/hourly/year=2022/month=3/day=7 to make sure perms are fixed after revert of T291664
- 19:13 ottomata: sudo -u hdfs kerberos-run-command hdfs hdfs dfs -chgrp -R analytics-privatedata-users /wmf/data/wmf/virtualpageview/hourly/year=2022/month=3/day=7 - revert of T291664
- 18:45 ottomata: sudo -u hdfs kerberos-run-command hdfs hdfs dfs -chgrp -R analytics-privatedata-users /wmf/data/wmf/mediacounts/year=2022/month=3/day=7
- 18:37 ottomata: sudo -u hdfs kerberos-run-command hdfs hdfs dfs -chgrp -R analytics-privatedata-users /wmf/data/wmf/webrequest/webrequest_source=text/year=2022/month=3/day=7 - after reverting - T291664
- 18:34 ottomata: restarting hive-server2 on an-coord1001 to revert hive.warehouse.subdir.inherit.perms change - T291664
- 14:44 btullis: failing back hive services to an-coord1001
- 13:09 aqu_: About to deploy analytics/refinery - Migrate wikidata/item_page_link/weekly from Oozie to Airflow
- 12:45 aqu_: About to deploy airflow-dags/analytics - Migrates wikidata/item_page_link
- 12:10 btullis: restarted hive-server2 process on an-coord1001
- 11:52 btullis: obtaining heap dump: `hive@an-coord1001:/srv/hive-tmp$ jmap -dump:format=b,file=hive_server2_heap_T303168.bin 16971`
- 11:51 btullis: obtaining summary of heap objects and sizes: `hive@an-coord1001:/srv/hive-tmp$ jmap -histo:live 16971 > hive-object-storage-and-sizes.T303168.txt`
- 11:38 btullis: failing over hive to an-coord1001 T303168
2022-03-05
[edit]- 10:03 elukey: restart hadoop-yarn-nodemanager on an-worker1132 (unhealthy node, reason Linux Container Executor reached unrecoverable exception)
2022-03-04
[edit]- 17:46 mforns: deployed Airflow to analytics instance to fix skein logs problem
- 15:50 mforns: deployed airflow in an-test-client1001 to test skein log fix
- 05:19 milimetric: rerunning monthly edit hourly druid oozie coordinator
2022-03-03
[edit]- 17:48 ottomata: roll restart aqs to pick up new MW history snapshot
2022-03-01
[edit]- 18:38 SandraEbele: sandra testing
- 18:34 razzi: demo irc logging to data eng team members
- 10:19 btullis: btullis@an-coord1002:/srv$ sudo rm -rf an-coord1001-backup/ (#T302777)
- 09:48 elukey: elukey@stat1004:~$ sudo kill `pgrep -u zpapierski` (offboarded user, puppet broken on the host)
2022-02-28
[edit]- 16:00 milimetric: refinery done deploying and syncing, new sqoop list is up
- 15:01 milimetric: deploying new wikis to sqoop list ahead of sqoop job starting in a few hours
2022-02-25
[edit]- 17:00 milimetric: rerunning webrequest-load-wf-text-2022-2-25-15 after confirming all false positive loss
2022-02-23
[edit]- 23:00 razzi: sudo maintain-views --table flaggedrevs --databases fiwiki on clouddb1014.eqiad.wmnet and clouddb1018.eqiad.wmnet for T302233
2022-02-22
[edit]- 10:37 btullis: re-enabled puppet on an-launcher1002, having absented the network_internal druid load job
- 09:30 aqu: Deploying analytics/refinery on hadoop-test only.
- 07:38 elukey: systemctl reset-failed mediawiki-history-drop-snapshot on an-launcher1002 (opened since a week ago)
- 07:30 elukey: kill remaining processes of rhuang-ctr on stat1004 and an-test-client1001 (user offboarded, but still holding jupyter notebooks etc..). Puppet was broken trying to remove the user.
2022-02-21
[edit]- 17:55 elukey: kill remaining processes of rhuang-ctr on various stat nodes (user offboarded, but still holding jupyter notebooks etc..). Puppet was broken trying to remove the user.
- 16:58 mforns: Deployed refinery using scap, then deployed onto hdfs (aqs hourly airflow queries)
2022-02-19
[edit]- 12:21 elukey: stop puppet on an-launcher1002, stop timers for eventlogging_to_druid_network_flows_internal_{hourly,daily} since no data is coming to the Kafka topic (expected due to some work for the Marseille DC) and it keeps alarming
2022-02-17
[edit]- 16:18 mforns: deployed wikistats2
2022-02-16
[edit]- 14:13 mforns: deployed airflow-dags to analytics instance
2022-02-15
[edit]- 17:20 ottomata: split anaconda-wmf into 2 packages: anaconda-wmf-base and anaconda-wmf. anaconda-wmf-base is installed on workers, anaconda-wmf on clients. The size of the package on workers is now much smaller. Installing throught the cluster. relevant: T292699
2022-02-14
[edit]- 17:38 razzi: razzi@an-test-client1001:~$ sudo systemctl reset-failed airflow-scheduler@analytics-test.service
- 16:08 razzi: sudo cookbook sre.ganeti.makevm --vcpus 4 --memory 8 --disk 50 eqiad_B datahubsearch1002 for T301383
2022-02-12
[edit]- 08:50 elukey: truncate /var/log/auth.log to 1g on krb1001 to free space on root partition (original log saved under /srv)
2022-02-11
[edit]- 15:06 ottomata: set hive.warehouse.subdir.inherit.perms = false - T291664
2022-02-10
[edit]- 18:54 ottomata: setting up research airflow-dags scap deployment, recreating airflow database and starting from scractch (fab okayed this) - T295380
- 16:48 ottomata: deploying airflow analytics with lots of recent changes to airflow-dags repository
2022-02-09
[edit]- 17:41 joal: Deploy refinery onto HDFS
- 17:05 joal: Deploying refinery with scap
- 16:39 joal: Release refinery-source v0.1.25 to archiva
2022-02-08
[edit]- 07:27 elukey: restart hadoop-yarn-nodemanager on an-worker1115 (container executor reached unrecoverable exception, doesn't talk with the Yarn RM anymore)
2022-02-07
[edit]- 18:43 ottomata: manually installing airflow_2.1.4-py3.7-2_amd64.deb on an-test-client1001
- 14:38 ottomata: merged Set spark maxPartitionBytes to hadoop dfs block size - T300299
- 12:17 btullis: depooled aqs1009
- 11:59 btullis: depooled aqs1008
- 11:41 btullis: depooled aqs1007
- 11:03 btullis: depooled aqs1006
- 10:22 btullis: depooling aqs1005
2022-02-04
[edit]- 16:05 elukey: unmask prometheus-mysqld-exporter.service and clean up the old @analytics + wmf_auto_restart units (service+timer) not used anymore on an-coord100[12]
- 12:55 joal: Rerun cassandra-daily-wf-local_group_default_T_pageviews_per_article_flat-2022-2-3
- 07:12 elukey: `GRANT PROCESS, REPLICATION CLIENT ON *.* TO `prometheus`@`localhost` IDENTIFIED VIA unix_socket WITH MAX_USER_CONNECTIONS 5` on an-test-coord1001 to allow the prometheus exporter to gather metrics
- 07:09 elukey: cleanup wmf_auto_restart_prometheus-mysqld-exporter@analytics-meta on an-test-coord1001 and unmasked wmf_auto_restart_prometheus-mysqld-exporter (now used)
- 07:03 elukey: clean up wmf_auto_restart_prometheus-mysqld-exporter@matomo on matomo1002 (not used anymore, listed as failed)
2022-02-03
[edit]- 19:35 joal: Rerun virtualpageview-druid-monthly-wf-2022-1
- 19:32 btullis: re-running the failed refine_event job as per email.
- 19:27 joal: Rerun virtualpageview-druid-daily-wf-2022-1-16
- 19:12 joal: Kill druid indexation stuck task on Druid (from 2022-01-17T02:31)
- 19:09 joal: Kill druid-loading stuck yarn applications (3 HiveToDruid, 2 oozie launchers)
- 10:04 btullis: pooling the remaining aqs_next nodes.
- 07:01 elukey: kill leftover processes of decommed user on an-test-client1001
2022-02-01
[edit]- 20:05 btullis: btullis@an-launcher1002:~$ sudo systemctl restart refinery-sqoop-whole-mediawiki.service
- 19:01 joal: Deploying refinery with scap
- 18:36 joal: Rerun virtualpageview-druid-daily-wf-2022-1-16
- 18:34 joal: rerun webrequest-druid-hourly-wf-2022-2-1-12
- 17:43 btullis: btullis@an-launcher1002:~$ sudo systemctl start refinery-sqoop-whole-mediawiki.service
- 17:29 btullis: about to deploy analytics/refinery
- 12:28 elukey: kill processes related to offboarded user on stat1006 to unblock puppet
- 11:09 btullis: btullis@an-test-coord1001:~$ sudo apt-get -f install
2022-01-31
[edit]- 14:51 btullis: btullis@an-launcher1002:~$ sudo systemctl start mediawiki-history-drop-snapshot.service
- 14:03 btullis: btullis@an-launcher1002:~$ sudo systemctl start mediawiki-history-drop-snapshot.service
2022-01-27
[edit]- 08:15 joal: Rerun failed cassandra-daily-wf-local_group_default_T_pageviews_per_article_flat-2022-1-26
2022-01-26
[edit]- 15:54 joal: Add new CH-UA fields to wmf_raw.webrequest and wmf.webrequest
- 15:44 joal: Kill-restart webrequest oozie job after deploy
- 15:40 joal: Kill-restart edit-hourly oozie job after deploy
- 15:27 joal: Deploy refinery to HDFS
- 15:10 elukey: elukey@cp4036:~$ sudo systemctl restart varnishkafka-eventlogging
- 15:10 elukey: elukey@cp4036:~$ sudo systemctl restart varnishkafka-statsv
- 15:06 elukey: elukey@cp4035:~$ sudo systemctl restart varnishkafka-eventlogging.service - metrics showing messages stuck for a poll()
- 14:56 elukey: elukey@cp4035:~$ sudo systemctl restart varnishkafka-webrequest.service - metrics showing messages stuck for a poll()
- 14:52 joal: Deploy refinery with scap
- 10:07 btullis: btullis@cumin1001:~$ sudo cumin 'O:cache::upload or O:cache::text' 'disable-puppet btullis-T296064-T299401'
2022-01-25
[edit]- 19:46 ottomata: removing hdfs druid deep storage from test cluster
- 19:37 ottomata: reseting test cluster druid via druid reset-cluster https://druid.apache.org/docs/latest/operations/reset-cluster.html - T299930
- 14:30 ottomata: stopping services on an-test-coord1001 - T299930
- 14:29 ottomata: stopping druid* on an-test-druid1001 - T299930
- 11:30 btullis: pooled aqs1011 T298516
- 11:29 btullis: btullis@puppetmaster1001:~$ sudo -i confctl select name=aqs1011.eqiad.wmnet set/pooled=yes
2022-01-24
[edit]- 21:18 btullis: btullis@deploy1002:/srv/deployment/analytics/refinery$ scap deploy -e hadoop-test -l an-test-coord1001.eqiad.wmnet
- 20:35 btullis: rebooting an-test-coord1001 after recreating the /srv/file system.
- 20:28 btullis: root@an-test-coord1001:~# mke2fs -t ext4 -j -m 0.5 /dev/vg0/srv
- 19:53 btullis: power cycled an-test-coord1001 from racadm
- 19:50 btullis: rebooting an-test-coord1001
- 19:19 ottomata: kill mysqld on an-test-coord1001 - 19:19:04 [@an-test-coord1001:/etc] $ sudo kill 42433
- 19:02 razzi: razzi@an-test-coord1001:~$ sudo systemctl stop presto-server
- 18:23 razzi: downtime an-test-coord1001 while attempting to fix /srv partition
- 11:48 elukey: roll restart of kafka test brokers to pick up the new keystore/tls-certs (1y of validity)
2022-01-22
[edit]- 08:36 elukey: `apt-get clean` on an-test-coord1001 to free some space
2022-01-21
[edit]- 01:03 milimetric: rerunning the eventlogging_to_druid_network_flows_internal-sanitization_daily timer that failed to get logs
2022-01-20
[edit]- 11:58 btullis: re-enabled puppet on all hive nodes, deploying the updated log4j configuration for parquet
- 11:36 btullis: temporarily disabling puppet on servers with hive installed T297734
- 07:49 joal: Rerun failed webrequest jobs (text and upload, 2022-01-19T19:00
2022-01-19
[edit]- 15:44 ottomata: installing anaconda-wmf_2020.02~wmf6_amd64.deb on all analytics cluster nodes. - T292699
- 14:00 ottomata: installing anaconda-wmf_2020.02~wmf6_amd64.deb on stat1004 - T292699
2022-01-17
[edit]- 07:19 elukey: launch webrequest bundle from 2022-01-16T01:00 (first hour missing for text) - 0003712-220113112502223-oozie-oozi-B
- 07:17 elukey: kill webrequest bundle, text coordinator failed (logs/info/etc.. https://hue.wikimedia.org/hue/jobbrowser/#!id=0024621-210701181527401-oozie-oozi-B)
- 07:13 elukey: umount/mount /mnt/hdfs on an-coord1001 to pick up java upgrades
2022-01-16
[edit]- 16:43 elukey: `elukey@an-launcher1002:~$ sudo systemctl reset-failed eventlogging_to_druid_network_internal_flows-sanitization_daily.service eventlogging_to_druid_network_internal_flows_daily.service eventlogging_to_druid_network_internal_flows_hourly.service
2022-01-13
[edit]- 12:41 joal: rerun failed instances of webrequest-load-coord
- 11:59 btullis: stopped eventlogging service on eventlog1003 with 1 hour's downtime.
- 11:52 btullis: Upgrading hive packages on stat1005
- 11:26 btullis: restarted hive-metastore and hive-server2 on an-coord1001 after running puppet.
- 11:23 btullis: btullis@an-coord1001:~$ sudo apt install hive hive-hcatalog hive-jdbc hive-metastore hive-server2 oozie oozie-client
- 11:18 btullis: btullis@an-coord1002:~$ sudo systemctl restart hive-metastore hive-server2
- 09:53 btullis: DNS change deployed, failing over hive to an-coord1002.
- 09:42 btullis: btullis@an-coord1002:~$ sudo apt install hive hive-hcatalog hive-jdbc hive-metastore hive-server2 oozie-client
- 08:45 joal: Kill-restart wikidata-json_entity-weekly-coord after deploy
2022-01-12
[edit]- 21:13 joal: Deploying refinery to HDFS
- 20:46 joal: Deploying refinery with scap
- 20:35 joal: refinery-source v0.1.24 released on archiva
- 11:25 elukey: move kafka-jumbo nodes to fixed kafka uid/gid
- 07:46 elukey: `systemctl reset-failed product-analytics-movement-metrics.service` on stat1007
2022-01-10
[edit]- 13:56 btullis: Upgrading oozie packages on an-test-coord1001 to test new log4j versions
2022-01-08
[edit]- 10:51 elukey: start hive-server2 on an-coord1002 - failed to connect to the metastore due to restart
- 10:41 elukey: restart hive daemons on an-coord1002 (after my last upgrade/rollback of packages the prometheus agent settings were not picked up, so no metrics)
2022-01-07
[edit]- 20:16 ottomata: altering hive table MobileWikiAppiOSUserHistory field event.device_level_enabled to string - T298721
- 17:29 btullis: deployed updated hive packages to an-test-worker100[1-3] and an-test-ui1001
- 14:52 btullis: root@aqs1014:~# jmap -dump:live,format=b,file=/srv/cassandra-b/tmp/aqs1014-b-dump202201071450.hprof 4468
2022-01-06
[edit]- 18:02 btullis: btullis@aqs1010:~$ sudo systemctl restart cassandra-a.service
- 12:22 btullis: restarting cassandra-a service on aqs1004.eqiad.wmnet in order to troubleshoot logging.
- 11:24 btullis: restarting cassandra-a service on aqs1010.eqiad.wmnet in order to troubleshoot logging.
- 08:12 joal: Rerun failed webrequest-load-wf-text-2022-1-6-7
- 07:58 joal: Rerun refine_event_sanitized_analytics_immediate missing hours after errors from the past days
- 07:39 joal: Rerun failed refine_eventlogging_analytics for mobilewikiappiosuserhistory schema, hours 2022-01-05T2[123]:00:00 and 2022-01-06T00:00:00, dropping malformed rows as discussed with schema owner
2022-01-05
[edit]- 19:16 joal: Rerun failed refine_eventlogging_analytics for mobilewikiappiosuserhistory schema, hours 2022-01-04T1[5789]:00:00, dropping malformed rows as discussed with schema owner
- 11:37 btullis: Upgrading hive on an-test-client1001 in order to test log4j upgrade
- 11:35 btullis: Upgrading hive packages on an-test-coord1001 to test log4j changes.
2022-01-04
[edit]- 10:39 elukey: restart cassandra-a on aqs1010 (heap size used in full, high GC)
- 10:20 elukey: restart cassandra-a on aqs1015 (heap size used in full, high GC)
2022-01-03
[edit]- 18:26 joal: rerun cassandra-daily-wf-local_group_default_T_mediarequest_per_file-2022-1-1
- 16:08 joal: Kill cassandra3-local_group_default_T_mediarequest_per_file-daily-2022-1-1
- 11:26 elukey: restart cassandra-b on aqs1015 (instance not responding, probably trashing)
- 11:16 elukey: restart cassandra-b on aqs1010 (stuck trashing)
- 10:34 elukey: depool aqs1010 (`sudo -i depool` on the node) to allow investigation of the cassandra -b instance
- 10:22 elukey: powercycle an-worker1114 (CPU soft lockup errors in mgmt console)
- 10:20 elukey: powercycle an-worker1120 (CPU soft lockup errors in mgmt console)
Archives
|
|---|
|
|