
Article feedback/Research/February 2011
Overview
[edit]We ran a new series of analyses based on data from the Phase 1 Article Feedback tool to try and address a number of research questions that may help inform the design/implementation of this tool. The analysis at this stage is exploratory and we will delve into the preliminary findings further over the coming weeks. Feedback is always appreciated in the talk page.
Research questions
[edit]The questions that we considered for the present study are the following:
- Are ratings reliable indicators of article quality?
- Are there correlations between measurable features of an article (size, number of citations, views, quality-related templates) and the volume/quality of ratings?
- Do different classes of users (anonymous vs. registered) rate articles differently and consistently within the same group?
- What factors drive conversions (i.e. the decision to rate an article after visiting it)?
- Are there significant changes over time in rating?
- Do changes in article features produce shifts in ratings or rating volume?
We decided to focus on well sourced ratings in particular as an initial case study to try an understand the relation between the presence of citations vs. source/citation needed templates (or lack thereof) on the one hand and the perceived quality of the article on the other hand.
Main findings
[edit]- A large majority of ratings are produced by anonymous users
- The sample is not representative of Wikipedia as a whole, as long, mature articles are overrepresented.
- The volume of daily ratings an article produces is proportional to the volume of daily views: the more popular an article is, the more daily ratings it will generate.
- Conversions decrease quickly for longer articles: either people are less motivated to rate long articles or they just don't see the feedback tool if it's positioned at the bottom of a long article.
- The length of an article and the number of citations it contains are good predictors of its mean well sourced score. Citations and length tend to be highly correlated, especially for mature articles.
- Above a certain length, raters do not seem to be able to discriminate article quality any further.
- For shorter articles, some quality scores (well sourced and complete) are more sensitive to length than others (neutral and readable).
- Rating completion rates are very high: people tend to fill in ratings along all four dimensions when they decide to rate an article.
- well-sourced and complete judgments tend to go together in the raters' perception of article quality, while they tend to be less correlated with judgments along the other two dimensions.
The dataset
[edit]The sample consists of a total of 727 articles selected from the PPI project + an additional list of articles related to special events. We collected ratings for articles in this sample between September 2010-January 2011 (hereafter: "observation period") for a total of 52787 ratings, 94.3% of which were generated by anonymous users vs. 5.7% by registered users. The mean number of ratings is 72 per article but, as expected, the distribution of ratings/article was very skewed, as detailed below. On top of ratings available from the Article Feedback tool, we obtained the following data:
- daily volume of article views (from http://stats.grok.se)
- daily changes in article length (via the Wikipedia API)
- daily changes in number of citations (via the Wikipedia API)
- daily changes in the number of citation/source needed templates (via the Wikipedia API)
Descriptive statistics
[edit]Article Length
[edit]The list of articles selected for this study is not a random sample of Wikipedia articles and as such it shouldn't be considered representative of Wikipedia articles at large. In particular, the sample includes articles that were already at a very mature stage at the beginning of the observation period (such as en:United States) or articles that were created from scratch and underwent a dramatic volume of edits during the observation period (such as the en:GFAJ-1 article). As a result articles in the sample differ substantially in initial size and in how much they changed during the observation period, both in absolute terms (total number of bytes added) or relative terms (proportion of bytes added with respect to the initial size).
- Fig.1 - Article length distribution
-
 Histogram of article lengths (AF sample vs. random sample from English Wikipedia).
Histogram of article lengths (AF sample vs. random sample from English Wikipedia). -
 Box plot of article lengths, Log-transformed (AF sample vs. random sample from English Wikipedia).
Box plot of article lengths, Log-transformed (AF sample vs. random sample from English Wikipedia).


| AF sample | enwiki | |
|---|---|---|
| Min | 472 | 9 |
| 25% | 5842 | 1402 |
| Median | 14190 | 2610 |
| 75% | 33257 | 5281 |
| Max | 188495 | 395786 |

Figure 1 (left) shows the distribution of article lengths in the Article Feedback sample (light blue) using Log-spaced bins, compared with the distribution of lengths of content articles from the English Wikipedia (light red, random sample of the same size).
Figure 1 (right) represents the same distributions as a box plot (using a Log-transformation of the lengths).
These plots suggest that:
- the distribution of article lengths is strongly right-skewed both for the AF sample and for the entire English Wikipedia
- the sample considered in this study, however, clearly overrepresents long articles compared to the whole English Wikipedia.
Figure 2 shows the distribution of relative length change during the observation period (top) and the relation between relative length change and initial length (bottom). Length plays a central role in quality ratings, but as the scatterplot in figure 2 shows, the majority of articles in the sample tend to start with a fairly large size and undergo changes during the observation period that are smaller than the initial length.
Cases with a relative change higher than 100% of the initial length tend to occur only for smaller articles, where relatively small contributions can create large relative changes.
Rating volume
[edit]Articles in the sample differ significantly in the volume of ratings they generate, with a strongly skewed distribution of the number of ratings per article across all four rating dimensions. Figure 3 shows a histogram with the distribution of the total number of ratings per article, with logarithmically spaced bins.

However, it's interesting to note that the completion rate for articles that get rated is very high, i.e. when people decide to rate an article, they consistently do so along all four dimensions. Figure 4 compares the volume of ratings per article along different dimensions (each dot represents an individual article) and shows a very strong linear correlation between the number of ratings an article produces across any 2 dimensions. To put it differently, it's very rare for articles to display a very high number of ratings in one dimension only with few ratings in the other 3 dimensions.

Views
[edit]We included the number of daily views per article as a control variable in the present analysis. Comparing traffic for articles in the sample shows that views vary dramatically not only in volume (popular vs. less popular articles) but also in how they vary over time (see Figure 5 below). Some articles (such as en:United States) display regular weekly fluctuations (together with seasonal fluctuations, i.e. less views during the winter holidays season), however the monthly volume of views tends to be roughly constant over time. In contrast, other articles referring to temporally identifiable events (such as en:Black Friday (shopping)) display strong peak in views around a specific date preceded and followed by a long period of silence. Other articles (such as en:DREAM Act) display multiple peaks in daily views as a function of increased coverage of issues and events in the media.
- Fig.5 - Article views
-
 Weekly + seasonal fluctuations
Weekly + seasonal fluctuations -
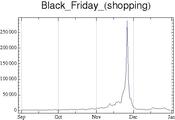 Single peak
Single peak -
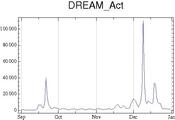 Multiple peaks
Multiple peaks



Conversions
[edit]We will refer to conversions as the number of users who actually decide to submit a rating when viewing an article. The conversion rate will be expressed as the proportion of ratings per number of views over a given period (e.g. one day).
Factors affecting rating volume
[edit]Views
[edit]As one would expect, the volume of daily ratings an article produces is strongly dependent on the total number of views it gets per day. Peaks and dips in the volume of daily ratings are aligned with peaks and dips in views, no matter how irregular visit patterns are.
- Fig. 6 - Article views (normalized) and daily ratings
-

-

-




- Fig. 7 - Daily volume of conversions (ratings/views)
-

-

-




Article length
[edit]Possibly the most interesting finding in the present analysis is that the probability for people to rate an article when they visit it decays at a very fast rate (following a power law relation) with the size of the article.

The trend in Figure 8 suggests that :
- Users don’t seem to bother using the feedback tool for long articles. This could be interpreted as either (1) the fact that the current positioning of the feedback tool at the bottom of a long article decreases the chances that people actually see it or (2) that people are less incentivized to rate an article when it's very long. This is partly consistent with the hypothesis defended by some scholars that feedback is more likely to occur when information is of bad quality or contains major inaccuracies.
- No matter what the explanation for this is, we should expect the volume of ratings to be skewed towards shorter (and presumably lower quality) articles.
Factors affecting rating scores
[edit]Article Length
[edit]Article length is a good predictor of rating scores, but it affects individual quality dimensions in different way. Rating scores for shorter articles, in particular, tend to be sensitive to length only when users assess completeness/well-sourcedness, but insensitive to length in the case of neutrality or readability. Above a specific article length threshold, rating scores tend to become consistent and do not correlate further with length: further increases in article length above this threshold won't produce any difference in the perception of quality by raters.
Figure 9 shows the relation between average length and average rating score along the 4 quality dimensions for longer articles (>50Kb). For articles in this category, average rating scores do not vary with length, suggesting that at this length they are consistently perceived as articles of a good quality and further increases in length do not seem to produce shifts in average article scores. Interestingly the distribution of average scores for this class of articles is comparable across all 4 dimensions.
Conversely, if we focus on shorter articles (<50Kb, Figure 10) we observe that length tends to be much more correlated with average scores, but it only does so in the case of well sourced and complete ratings (highlighted, light gray). This is consistent with the intuition that article length should not be a critical factor for an article to be perceived as neutral or readable (i.e. there is no reason why short articles should be perceived as less neutral or less readable than longer ones), while there are reasons to believe that this should be the case for well sourced and complete ratings.



If we focus on the case of well sourced scores, in particular, and consider the difference in score between the longest and shortest articles we see that length has an important effect.
Figure 11 shows the relation between average length and average quality score (well sourced) for a sample of 300 articles with the largest volume of ratings. Articles in red are the top 50 by length, articles in blue are the lowest 50 by length, the two classes of articles tend to separate into two fairly distinct groups based on individual average rating scores.
The two tables below show the mean well sourced score for the 10 longest (Table 2) and the 10 shortest entries (Table 3) in the above sample of frequently rated articles. Note the large difference in rating volume within each series.
| Article | Length (bytes) | Mean WS score | WS rating volume |
|---|---|---|---|
| en:Barack_Obama | 212673 | 4.09 | 2277 |
| en:Michael_Jackson | 189541 | 4.30 | 2700 |
| en:United_States | 167228 | 4.20 | 298551 |
| en:Speed_limits_in_the_United_States | 153070 | 4.41 | 3808 |
| en:Philippines | 144370 | 4.17 | 420 |
| en:Health_care_in_the_United_States | 143953 | 4.18 | 4418 |
| en:USA_PATRIOT_Act | 143890 | 4.15 | 11424 |
| en:India | 140747 | 4.21 | 34561 |
| en:San_Francisco | 140633 | 3.71 | 770 |
| en:David_Beckham | 137894 | 4.60 | 2950 |
| Article | Length (bytes) | Mean WS score | WS rating volume |
|---|---|---|---|
| en:International_Year_of_Chemistry | 3930 | 3.71 | 1192 |
| en:International_Year_of_Forests | 3801 | 3.57 | 504 |
| en:Time_shifting | 3495 | 3.23 | 265 |
| en:83rd_Academy_Awards | 3332 | 4.13 | 23301 |
| en:COTS_Demo_Flight_2 | 3162 | 3.80 | 410 |
| en:Fly_America_Act | 2534 | 2.13 | 432 |
| en:Blue_Code_of_Silence | 2381 | 2.90 | 545 |
| en:Dual_federalism | 1944 | 2.24 | 288 |
| en:5_centimeter_band | 913 | 2.12 | 354 |
| en:2011_NBA_Playoffs | 899 | 4.23 | 536 |
Number of citations
[edit]We found a similar correlation between average quality score and average number of citations, albeit weaker: the higher the difference in average number of citations between two classes of articles in the sample, the larger the gap in the average quality score these articles obtain for the well sourced dimension. Further analyses will look at the effects of citation needed templates on the perceived quality of an article.


On closer inspection, the number of citations and the length of an article tend to be highly correlated, especially as length increases, as illustrated in figure 12.
It is also interesting to note that for particularly mature articles, further editor activity tends to focus on sourcing content via citations and references and expanding articles in ways that preserve the previous density of references/citations per unit of content. In other words: the probability for large chunks of text to be added to mature articles without adding a comparable number of references tends to be very low.
Figure 13 represents the daily variations in length and in number of citations for article en:United States: the plots show that macroscopic changes in one dimension are temporally correlated with changes in the other dimension.
The two tables below show the mean well sourced score for the 10 most referenced (Table 4) and 10 of the least referenced entries (Table 5) in the above sample of frequently rated articles. Citations correspond to the number of cite templates used in the article. Note again the large difference in rating volume within each series and the similarity between the 10 longest series above (Table 1) and 10 most referenced series.
| Article | Citations | Mean WS score | WS rating volume |
|---|---|---|---|
| en:Barack_Obama | 393 | 4.09 | 2277 |
| en:Michael_Jackson | 240 | 4.30 | 2700 |
| en:India | 232 | 4.21 | 34561 |
| en:United_States | 201 | 4.20 | 298551 |
| en:San_Francisco | 174 | 3.71 | 770 |
| en:Joran_van_der_Sloot | 163 | 4.58 | 3410 |
| en:California_Proposition_8_(2008) | 156 | 4.48 | 2565 |
| en:Gun_violence_in_the_United_States | 147 | 4.25 | 3045 |
| en:David_Beckham | 144 | 4.60 | 2950 |
| en:Patient_Protection_and_Affordable_Care_Act | 139 | 4.16 | 31396 |
| Article | Citations | Mean WS score | WS rating volume |
|---|---|---|---|
| en:Good_Neighbor_policy | 1 | 2.44 | 250 |
| en:5_centimeter_band | 1 | 2.12 | 354 |
| en:Federal_Bureau_of_Prisons | 1 | 3.50 | 364 |
| en:United_States_welfare_state | 1 | 2.83 | 424 |
| en:Federal_Aid_Highway_Act_of_1956 | 1 | 3.26 | 552 |
| en:Federal_Insurance_Contributions_Act_tax | 1 | 3.74 | 621 |
| en:Traffic | 1 | 3.77 | 732 |
| en:United_States_territorial_acquisitions | 1 | 3.34 | 3318 |
| en:History_of_immigration_to_the_United_States | 1 | 3.50 | 3828 |
| en:Fourteen_Points | 1 | 3.57 | 12760 |
Correlations across quality scores
[edit]Another question on which we focused is whether articles score similarly across all four dimensions or we can identify classes of articles scoring high on one dimension and low on the other dimensions. The results suggest that scores in some dimensions tend to be consistently correlated with respect to others. Score correlation is particularly strong for complete and well-sourced judgments, consistently with the results presented above suggesting that completeness and well-sourcedness tend to behave similarly.
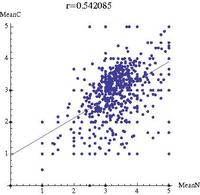

Figure 14 represents the mean score individual articles obtained in complete and neutral ratings, while figure 15 compares the mean score for individual articles in complete and well-sourced ratings. r is the Pearson correlation coefficient for each of the two pairs of series, measuring the strength of linear dependence between them: the dependence between complete and well-sourced scores tends to be much higher than between complete and neutral, consistently with the previous findings. When comparing different classes of raters, we also found that the above correlations are systematically stronger across all possible combinations of quality dimensions when ratings are produced by registered users than anonymous users, which is somewhat surprising (one would expect that registered users tend to be able to discriminate quality aspects better than anonymous users). It remains to be understood if articles happen to be at the same complete and well sourced (as suggested above) or the perception of quality along these two dimensions tends to align (suggesting that raters hardly make a difference between them when rating article quality).
Summary of findings
[edit]These are some preliminary conclusions we can draw from the present analysis:
- We found some important biases in the sample of articles we considered (e.g. a set mostly consisting of mature, fairly well-sourced articles), and as such it should not be taken as representative of the whole Wikipedia. We will be extending in the next phase the data collection to a larger (random) sample of Wikipedia articles on top of a number of special lists of articles, to try and get a more accurate picture of the functioning of ratings across all levels of quality and maturity of Wikipedia articles. Expanding the size of the sample will also allow us to increase the overall rating volume and the accuracy of the analyses, which in many cases suffered from a small number of available observations.
- Despite these biases in the sample, we can draw some preliminary conclusions on the relation between article features and their perceived quality on the one hand or the volume of total ratings they produce on the other hand. Beside the number of daily views, we found that the length of an article plays a prominent role among the factors affecting rating volume, suggesting that people tend to rate shorter articles. This implies that the positioning of the article feedback tool may be critical or that users on average feel less incentivised to rate the quality of articles above a certain length, but either way we should expect a bias in rating volumes favoring shorter articles.
- We also found a consistently strong correlation not only between the number of citations and the mean quality score of an article, but also between its length and the mean quality score. We will need to disambiguate between high scores due to citations and high scores due to length, but we showed that these two variables tend to be highly correlated across the sample, especially for the most mature articles. We also found evidence of a threshold above which further changes in length or number of citations do no seem to produce any visible effect on the average score of an article's quality and that below this threshold some kinds of ratings (neutral and readable) tend to be less sensitive to length than other (well-sourced and complete).
- The analysis of short-term changes on quality scores didn't reveal so far any significant effects, suggesting that changes in quality within a short observation period may be less important in driving quality judgments than the initial size and maturity of an article.
- Finally, we found evidence that, while completion rates are very high (i.e. people tend to fill in ratings along all four dimensions when they decide to rate an article), some quality dimensions tend to have a higher interdependence than others. In particular we found evidence across different analyses that well-sourced and complete judgments tend to go together and differ systematically from judgments along the other two dimensions.
Further research directions
[edit]Further research will focus on the following questions:
- Testing for significant shifts in mean score across the observation period for different classes of articles (e.g. by initial size, by relative magnitude of change)
- Testing whether in the proximity of the largest relative change in length scores change significantly
- Testing whether quality scores in peaks and valleys by number of views display significant differences
- Measuring correlations between length and quality scores for different article length bands
- Studying what other factors affect conversions
- Measuring changes in quality score variance over time to understand whether raters get more consistent when article length or maturity increases.
- Understanding what factors are most likely to produce:
- the largest increase in quality scores
- the largest change in the variance of quality scores
- the largest increase in rating volume
The implementation of v.2.0 of the Article Feedback tool will also allow to test:
- to what extent the level of expertise/prior knowledge of the rater is reflected in quality ratings
- whether ratings are an effective on-ramp for account creation and/or editing