
Moderator Tools/Automoderator
|
Automoderator
|
The Moderator Tools team is currently working on a project to build an 'automoderator' tool for Wikimedia projects. It will allow moderators to configure automated prevention or reversion of bad edits based on scoring from a machine learning model. In simpler terms, we're building software which performs a similar function to anti-vandalism bots such as ClueBot NG, SeroBOT, and Dexbot, but making it available to all language communities. A MediaWiki extension is now under development - Extension:AutoModerator.
Our hypothesis is: If we enable communities to automatically prevent or revert obvious vandalism, moderators will have more time to spend on other activities.
We will be researching and exploring this idea during the rest of 2023, and expect to be able to start engineering work by the start of the 2024 calendar year.
Latest update (February 2024): Designs have been posted for the initial version of the landing and configuration pages. Thoughts and suggestions welcome!
Previous updates[edit]
- February 2024: We have posted initial results from our testing process.
- October 2023: We are looking for input and feedback on our measurement plan, to decide what data we should use to evaluate the success of this project, and have made testing data available to collect input on Automoderator's decision-making.
- August 2023: We recently presented this project, and other moderator-focused projects, at Wikimania. You can find the session recording here.
Motivation[edit]
A substantial number of edits are made to Wikimedia projects which should unambiguously be undone, reverting a page back to its previous state. Patrollers and administrators have to spend a lot of time manually reviewing and reverting these edits, which contributes to a feeling on many larger wikis that there is an overwhelming amount of work requiring attention compared to the number of active moderators. We would like to reduce these burdens, freeing up moderator time to work on other tasks.
Many online community websites, including Reddit, Twitch, and Discord, provide 'automoderation' functionality, whereby community moderators can set up a mix of specific and algorithmic automated moderation actions. On Wikipedia, AbuseFilter provides specific, rules-based, functionality, but can be frustrating when moderators have to, for example, painstakingly define a regular expression for every spelling variation of a swear word. It is also complicated and easy to break, causing many communities to avoid using it. At least a dozen communities have anti-vandalism bots, but these are community maintained, requiring local technical expertise and usually having opaque configurations. These bots are also largely based on the ORES damaging model, which has not been trained in a long time and has limited language support.
Goals[edit]
- Reduce moderation backlogs by preventing bad edits from entering patroller queues.
- Give moderators confidence that automoderation is reliable and is not producing significant false positives.
- Ensure that editors caught in a false positive have clear avenues to flag the error / have their edit reinstated.
- Are there other goals we should consider?
Design research[edit]


We delved into a comprehensive design research process to establish a strong foundation for the configuration tool for Automoderator. At the core of our approach is the formulation of essential design principles for shaping an intuitive and user-friendly configuration interface.
We looked at existing technologies and best practices and this process is known as desk research. This allowed us to gain valuable insights into current trends, potential pitfalls, and successful models within the realm of automated content moderation. We prioritized understanding the ethical implications of human-machine learning interaction, and focused on responsible design practices to ensure a positive and understandable user experience. We honed in on design principles that prioritize transparency, user empowerment, and ethical considerations.
Model[edit]
This project will leverage the new revert risk models developed by the Wikimedia Foundation Research team. There are two versions of this model:
- A multilingual model, with support for 47 languages.
- A language-agnostic model.
These models can calculate a score for every revision denoting the likelihood that the edit should be reverted. We envision providing communities with a way to set a threshold for this score, above which edits would be automatically prevented or reverted.
The models currently only support Wikipedia, but could be trained on other Wikimedia projects. Additionally they are currently only trained on the main (article) namespace. Once deployed, we could re-train the model on an ongoing basis as false positives are reported by the community.
Before moving forward with this project we would like to provide opportunities for testing out the model against recent edits, so that patrollers can understand how accurate the model is and whether they feel confident using it in the way we're proposing.
- Do you have any concerns about these models?
- What percentage of false positive reverts would be the maximum you or your community would accept?
Potential solution[edit]


We are envisioning a tool which could be configured by a community's moderators to automatically prevent or revert edits. Reverting edits is the more likely scenario - preventing an edit requires high performance so as not to impact edit save times. Additionally, it provides less oversight of what edits are being prevented, which may not be desirable, especially with respect to false positives. Moderators should be able to configure whether the tool is active or not, have options for how strict the model should be, determine the localised username and edit summary used, and more.

Lower thresholds would mean more edits get reverted, but the false positive rate is higher, while a high threshold would revert a smaller number of edits, but with higher confidence.
While the exact form of this project is still being explored, the following are some feature ideas we are considering, beyond the basics of preventing or reverting edits which meeting a revert risk threshold.
Testing[edit]
If communities have options for how strict they want the automoderator to be, we need to provide a way to test those thresholds in advance. This could look like AbuseFilter’s testing functionality, whereby recent edits can be checked against the tool to understand which edits would have been reverted at a particular threshold.
- How important is this kind of testing functionality for you? Are there any testing features you would find particularly useful?
Community configuration[edit]
A core aspect of this project will be to give moderators clear configuration options for setting up the automoderator and customising it to their community’s needs. Rather than simply reverting all edits meeting a threshold, we could, for example, provide filters for not operating on editors with certain user groups, or avoiding certain pages.
- What configuration options do you think you would need before using this software?
False positive reporting[edit]
Machine learning models aren't perfect, and so we should expect that there will be a non-zero number of false positive reverts. There are at least two things we need to consider here: the process for a user flagging that their edit was falsely reverted so it can be reinstated, and providing a mechanism for communities to provide feedback to the model over time so that it can be re-trained.
The model is more sensitive to edits from new and unregistered users, as this is where most vandalism comes from. We don't want this tool to negatively impact the experience of good faith new users, so we need to create clear pathways for new users to understand that their edit has been reverted, and be able to reinstate it. This needs to be balanced with not providing easy routes for vandals to undo the tool's work, however.
Although these models have been trained on a large amount of data, false positive reporting by editors can provide a valuable dataset for ongoing re-training of the model. We need to figure out how to enable experienced editors to send false positive data back to the model so that it can improve over time.
- How could we provide clear information and actions for editors on the receiving end of a false positive, in a way which isn’t abused by vandals?
- What concerns do you have about false positives?
Designs[edit]
Our current plans for Automoderator have two UI components:
-
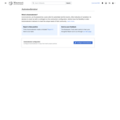 Landing page.
Landing page.

A landing page with information about Automoderator, a way to appeal the bot’s decisions, and a link to configure the bot.
-
 Configuration page.
Configuration page. -
 Making changes to the configuration page.
Making changes to the configuration page. -
 Saving changes to the configuration page.
Saving changes to the configuration page.



The configuration page, which will be generated by Community Configuration. In the MVP, admins will be able to turn Automoderator on or off, configure its threshold (i.e. how it should behave), and customize its default edit summary and username. We anticipate that we'll add more configuration options over time in response to feedback. Once the page is saved, if the user has turned Automoderator on, it will start running immediately.
Other open questions[edit]
- If your community uses a volunteer-maintained anti-vandalism bot, what has your experience of that bot been? How would you feel if it stopped working?
- Do you think your community would use this? How would it fit in with your other workflows and tools?
- What else should we consider that we haven't documented above?