
Requests for comment/Media file request counts
| Media file request counts | |
|---|---|
| Component | General |
| Creation date | |
| Author(s) | Erik Zachte (WMF), Christian Aistleitner (WMF) |
| Document status | implemented |
Background[edit]
Since 2008 Wikimedia collects pageview counts for most pages on nearly all wikis. A longstanding request of stakeholders (editors, researchers, GLAM advocates) has been to publish similar counts for media files: images, sounds, videos. A major obstacle to effectuate this was the existing traffic data collecting software. Webstatscollector simply couldn't be scaled up further without incurring huge costs. Even page view counts weren't complete: no per page mobile counts, just per wiki.
In 2014 WMF engineers rolled out a new Hadoop based infrastructure, which makes it possible to collect raw request counts for media files. So a few months after releasing extended pageview counts (with mobile/zero added), the time has come to produce similar data dumps for media files.
Problem[edit]
What will be the exact specifications of the new media file request dumps?
Out of scope[edit]
This proposal is:
- not about reporting or visualization software. There are no plans yet at WMF to provide new tools that.
- This doesn't imply that these reports aren't very useful. They are. Just not immediate priority.
- not about higher aggregation of media file requests, e.g. totaling counts per category.
- There are experiments planned to import Wikimedia dumps into Hadoop, thus making the categorization hierarchy per wiki more readily available.
- not about geo-encoded traffic (based on ip address). ip->geo encoded data are not structurally available in the current version of the WMF Hadoop/Hive infrastructure.
- It is possible to run queries and geo-encode ip addresses, but that requires custom code, and throttling the data stream by e.g. sampling, and may have privacy consequences that need to be settled first.
Proposal[edit]
Definitions[edit]
- Media files
- All images, sound files and videos on the WMF upload servers (url '..//upload.wikimedia.org/..'), which are stored in a 'white listed' folder (see File paths below), and with a 'white listed' extension (see File extensions below)'.
- Note 1: These images are mostly embedded in articles, but can be requested separately.
- Note 2: Out of scope are therefor images which are served to users from e.g. the bits servers (e.g. navigation icons).
- Handler modifier
- Part of the url, which shows at which size and in which file format a media file was re-rendered (best term here?).
- This will be the last part of the url, if applicable, after the file name for the original file (see red texts in examples below).
- If this part of the url is not available, the image request will be considered to be for the original file.
- If it is available the (vertical) image size will be harvested from the string and used for counting this request as high or low quality image/video.
- e.g. https://upload.wikimedia.org/wikipedia/commons/thumb/4/4a/Commons-logo.svg/762px-Commons-logo.svg.png
- e.g. http://upload.wikimedia.org/wikipedia/commons/thumb/5/58/Stevejobs_Macworld2005.jpg/qlow-440px-Stevejobs_Macworld2005.jpg]
{kind=link}
{kind=link}
Packaging[edit]
Like with pageviews all requests per time unit (here: day) will be packaged into one file. Unlike with pageviews not much download speed could be gained from breaking different projects/wikis into separate files (under consideration), as most media files are stored in one wiki: Commons.
Update frequency[edit]
The proposed update frequency is daily dump files. Reason to choose for daily updates instead of say hourly updates (like with page views) are:
- Although generation of one daily file is even less efficient than 24 hourly updates, it requires less post-processing for aggregation (getting from hourly to daily, then monthly, totals).
- More convenient to download (due to much smaller per-day size)
- A drawback of only daily files seems acceptable, as there will be less need for hour-to-hour analysis of traffic compared to page views.
E.g. with major world events images tend to appear online with more delay (read asynchronously from events developing).
Filtering[edit]
File paths[edit]
Only requests with webrequest field "uri_host='upload.wikimedia.org'" are taken into consideration.
Only media files (inferred from file extension) will be included. Hence favicon.ico will be included, robots.txt will not.
Records for which the url does not correspond to a predefined pattern (as laid down in regular expressions) will be discarded. A separate background task will monitor sampled squid logs for these outliers, so that new patterns will be caught early on.
Currently four folder hierarchies on the upload servers are included: (red is -handler modifier-)
- //upload.wikimedia.org/ -project code- / [archive / ] -language code- / [thumb|transcoded / ] @ / @@ / -image file name- [ / -handler modifier-]
- e.g. http://upload.wikimedia.org//wikipedia/commons/4/4a/Commons-logo.svg
- e.g. https://upload.wikimedia.org/wikipedia/commons/thumb/4/4a/Commons-logo.svg/762px-Commons-logo.svg.png
- e.g. http://upload.wikimedia.org/wikipedia/commons/thumb/5/58/Stevejobs_Macworld2005.jpg/qlow-440px-Stevejobs_Macworld2005.jpg]
- e.g. http://upload.wikimedia.org/wikipedia/commons/thumb/7/7d/Will_Success_Spoil_Rock_Hunter_trailer.ogv/mid-Will_Success_Spoil_Rock_Hunter_trailer.ogv.jpg
- e.g. http://upload.wikimedia.org/wikipedia/commons/transcoded/b/bd/Xylophone_jingle.wav/Xylophone_jingle.wav.ogg
- e.g. http://upload.wikimedia.org/wikipedia/commons/transcoded/3/31/Lheure_du_foo.ogv/Lheure_du_foo.ogv.480p.webm
{kind=link}
{kind=link}
- //upload.wikimedia.org/math/ @ / @ / @ / -math image file name-
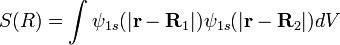{kind=link}
- //upload.wikimedia.org/ -project code- / @@ /timeline/ -timeline image file name-
{kind=link}
- //upload.wikimedia.org/math/score/ @ / @ / -score image file name-
{kind=link}
Legend:
- each @ stands for one character in range 0-9a-f, sometimes 0-9a-z
- -xxx- generic description
- [..] = optional segment
- language code includes strings like 'meta', 'commons' etc)
- ignore spaces
File extensions[edit]
Any file extension will be accepted, as long as the file exists in the proper file hierarchy, and can be parsed by existing regular expressions. Squid sample monitoring will reveal new outliers.
Hive source[edit]
Only requests flagged in Hive table webrequest as "webrequest_source='upload'" are taken into account (other valid values are 'bits', 'text', 'mobile')
Status codes[edit]

- The following status codes will be on the 'white list':
- 200 OK
- 206 Partial content (for streamed/timed content: movie or sound file) only include request for first (+/-7k) chunk
Note: not including 304 (Not modified) has been under long debate between the authors of this RFC. Do we want to count all requests about images to WMF servers? Then 304 definitely should be counted. These are mostly for images served from the cache, where the browser checks whether the image has changed (could be every few seconds, when a user visits many pages with the same navigation icon). In the end we decided to propose not to include 304. Thus for images the count goes more to 'files actually transferred' (except see next section 'Prefetched images').
Caveat: for browsers with cache disabled, we would still count those repeating navigation icons on every page visit.
Prefetched images[edit]
Whenever imageviewer is started it downloads two images, one which the user asked for (by clicking a thumbnail), and one which the user might ask for next by clicking right arrow. Whenever the user does click right arrow a new image is prefetched (if more unseen images are available). The proposal is to not count those prefetched images which never ended up being shown to the user.
Without this measure, if imageviewer becomes the default method to view large images on desktops, the image File:Mona_Lisa,_by_Leonardo_da_Vinci,_from_C2RMF_retouched.jpg would make File:Mona Lisa margin scribble.jpg one of the most viewed images on Wikipedia, where in reality it is almost never shown to the user.
{kind=link}
{kind=link}
Patches for this (by Gilles Dubuc, done at Amsterdam GLAM hackaton) are already up for review:
- Patch 173515 checks how many image views we'd be missing in Media Viewer if we used onbeforeunload to measure them. It's an underlying technical exploration for the commit below.
- Patch 173641 marks Media Viewer's image/thumbnail GET requests. This will let us filter Media Viewer's queries out of server logs. Which is necessary since Media Viewer preloads some images without them necesseraly ending up being viewed by users.
Note: this doesn't mean that all images which have not been shown to the user are discounted. If a user doesn't scroll down to the last part of long page and thus hasn't seen some of thumbnails at hte bottom of the page, that doesn't disqualify those thumbnails from being counted. Unlike many prefetched images these image were rendered on a html page and we simply can't tell if the user scrolled down. That would require feedback via javascript and we don't want to do that (privacy issues, complexity).
Aggregation level[edit]
by project/wiki[edit]
This happens implicitly, as -project code- and -language code- are part of the file path. Note that language code can also be e.g. 'commons' or 'meta'.
file extension[edit]
Media files can be uploaded in many formats. We consider files with different file extensions as totally unrelated entities. E.g. blob.png and blob.jpg may show the same picture in the same size, etc, but that is not relevant here.
Exception: system side file format conversions, rendering svg files as png, are not considered separate entities as the -handler modifier- is stripped from the path
Example:e.g. https://upload.wikimedia.org/wikipedia/commons/thumb/4/4a/Commons-logo.svg/762px-Commons-logo.svg.png (red is -handler modifier-)
by rendered size[edit]

Content can be requested in a variety of pre-rendered/custom rendered versions. This goes particularly for images where thumbs can be requested in any size.
by revision[edit]
Images in ../archive/.. will be counted separately
(!! how about revisions of timelines ?)
by http referer[edit]
internal/external/unknown
One aggregation level could be: source of request (aka http referer): internal/external/unknown.
In Oct 2014 a quick scan showed referers for media files on uploads servers were
- ~92,5% internal (known)
- 4,3% unknown
- 3,2% external (known)
Reason to include external referers separately: Half of the bandwidth in Oct 2014 was consumed by external sites which either include Wikimedia's media files directly in their page (BTW not forbidden by Wikimedia's policies), or provide a direct link to Wikimedia media file. The vast majority of internal media files are thumb images with negligible impact on bandwidth, hence the different breakdown for files counts and bytes sent.
mobile vs non-mobile site
Another level could be 'internal referer main site' vs 'internal referer mobile site' but this information about mobile/non mobile seems too shaky too use (e.g. many apps do not properly list referer)
Also secure traffic (https) doesn't list referer.
by context[edit]
During the Nov 2014 GLAM hackaton the following was proposed and seemed pretty straightforward to implement (quoting WMF engineer here, but of course that was an initial quick assessment only) : allow images to be counted by context in which they appear. If a url parameter were to be added by parser for file upload page (namespace 6) and thumb and frame image links, and by imageviewer, we could collect more meaningful stats, not having to infer image use from thumbnail size (which would remain very fuzzy at best). We propose to use the [X-Analytics] format for these new tags.
Encoding[edit]
File name encoding will be standardized, doing away with many browser artifacts (browsers may encode a url differently). This reduces the number of meaningless variations in actual file names, which otherwise would be counted separately and have to be merged in post-processing. (an issue that exists for pageview counts, where all requested url's are counted as they are received).
File names will be decoded, then encoded (to avoid double encoding) with a custom function IdentifyMediaFileUrl.java
File format[edit]
Headers[edit]
It would be helpful to have column headers on the first line of the data file. But generating these directly from the Hive query may be difficult, to be investigated. If postprocessing the file (uncompress, add line, compress) just for this headers line is needed that seems not worth it.
Field separator[edit]
Tabs as field separators seems most conforming to new WMF operations conventions, and inclined to break than e.g. comma's or spaces. But chime in if you think different, and please explain why.
Empty values[edit]
Nearly all fields are counts, and 'none found' will just be '0'
Other empty values (if any?) will be shown as '-' (dash), rather than Hive default NULL.
File compression[edit]
Unlike page view dumps this file will be published as .bz2 (test shows 20% further reduction in size compared to .gz).
A test file for one day in Oct 2014 contained approx 108MB in bz2 format.
Sort order[edit]
Sensible options for sort seem to be:
- alphabetical by first field (will compress best)
- numerical by total request (lots of tiny navigation icons will top the list)
- numerical by high quality requests (advised)
The last option had a small added benefit of showing most popular images of decent size first, thus taking away the need of a sort step for e.g. top 100 lists.
Fields[edit]
Some fields are (based on) native fields in Hive table webrequests. Some fields are (based on) derived fields via a user defined function (UDF), see https://gerrit.wikimedia.org/r/#/c/169346/ gerrit patch.
Set of fields to show[edit]
- mediafile/base_name/media_base_path (name to decide)
- total bytes sent
- Usefulness has been under serious debate: For some file types bytes sent is a good approximation of files sizes transferred, as files have already been compressed, e.g. png,jpg,tiff. For other types (e.g. pdf) this is not the case, bytes transferred may be rather meaningless here.
- total files requested
- total files requested, original format
- total files requested, image thumbnails width till 199
- total files requested, image thumbnails width from 200 till 399
- total files requested, image thumbnails width from 400 till 599
- total files requested, image thumbnails width from 600 till 799
- total files requested, image thumbnails width from 800 till 999
- total files requested, image thumbnails width from 1000
- total files requested, video thumbnails width till 239
- total files requested, video thumbnails width from 240 till 479
- total files requested, image thumbnails width from 480 and above
- total files requested, from internal referer, any size
- total files requested, from external referer, any size
- total files requested, from unknown referer, any size
- total files requested, where context is image thumbnail or image frame (on e.g. article page or category page, but all namespaces except ns 6 would qualify)
- total files requested, where context is imageviewer (and not a prefetched image that never got to be shown)
- total files requested, where context is file details page, aka file upload page
- total files requested, where context is navigation (reserved column, no implementation decided yet)
Caveat: Interpreting most requested image/video sizes will always be hard, as user device type comes into play. Unfortunately breaking down by device type is not feasible in this context.
Field specifics[edit]
- mediafile (aka base_name)
Definition: The actual url under which the original media file can be accessed, minus 'http(s)://upload.wikimedia.org/' and minus '-handler modifier-'
The choice to not further breakdown this field into project code, language code, and file name is for two reasons:
- The data dumps will be processed by scripts only
- Now it is easy to manually check the actual content of the file by prefixing the field content with 'http(s):////upload.wikimedia.org/' and pasting into a browser address bar.
(!! base_name? mediafile? it contains part of the path, so its not a file name, yet base_name is rather nondescript, what about media_path? media_base_path? )
- bytes
Definition: 'The number of bytes sent resulting from all requests for a image or sound file, regardless of size or referer'
- Note 1: Transport size does not have to match file size, there may transport encoding (but most files are compressed already)
- Note 2: For video files where data are mostly streamed, and the user can skip back or rewind, the exact definition, or even usefulness of this field is under discussion.
- Note 3: Where field 'bytes sent' in page views data file hasn't seen much (or any) usage over the years, changes are this will be different for media files, as these tend to be very much larger, and resource/bandwidth analysis/monitoring might be more relevant here.